
|
1 Document Overview
1.1 Scope and Purpose
This document provides an engineering guide to the file formats used by SQLite to store databases on disk. It also contains a description of the file locking protocol used by SQLite to control read and write access to the files and other protocols for safely modifying the database in a live system (one that may contain other database clients). It is intended that this document shall provide all the information required to create an system that reads and writes SQLite databases in a way that is completely compatible with SQLite itself. There are two broad purposes for providing this information:
To make it easier to maintain, test and improve the SQLite software library.
To facilitate the development of external (non-SQLite) software that may operate directly on SQLite databases stored within a file-system. For example a database space analysis utility or a competing database client implementation.
A shorter and more recent second edition file format document also available. The two file format descriptions are independently written and hence serve as cross-checks of one another. Any incompatibilities between the two documents should be considered a bug.
The availability of this information makes an SQLite database an even safer choice for long-term data storage. If at some point in the future the SQLite software library cannot be used to access an SQLite database that contains useful data, a procedure or software module may be developed based on the content of this document to extract the required data.
None of the information contained in this document is required by programmers wishing to use the SQLite library in applications. The intended audience is engineers working on SQLite itself or those interested in creating alternative methods of accessing SQLite databases (without using SQLite).
1.2 Document and Requirements Organization
The content of this document is divided into three sections.
Section 2 describes the format of a database image. A database image is the serialized form of an SQLite database that is stored on disk.
Usually, an SQLite database image is stored in a single file on disk, an SQLite database file. However, while the database image as stored on disk is being modified, it may be temporarily stored in a more convoluted format, distributed between two files, the database file and a journal file. If a failure occurs while modifying a database image in this fashion, then the database image must be extracted from the database and journal files found in the file-system following recovery (other documentation refers to this as "hot journal rollback"). Section 3 describes the format used by the journal file and the rules for correctly reading a database image from the combination of a database file and journal file.
Section 4 contains descriptions of and software requirements related to other protocols that must be observed by software that reads and writes SQLite databases within a live system, including:
- requirements governing the integrity of database file-system representations,
- the locking protocol used by SQLite to manage read and write access to the database and journal files within the file-system, and
- the change-counter and schema-cookie protocols that must be followed by all database writers to facilitate the implementation of efficient in-memory caches of the database schema and content by readers and writers.
1.3 Glossary
| Auto-vacuum last root-page | A page number stored as 32-bit integer at byte offset 52 of the database header (see section 2.2.1). In an auto-vacuum database, this is the numerically largest root-page number in the database. Additionally, all pages that occur before this page in the database are either B-Tree root pages, pointer-map pages or the locking page. |
| Auto-vacuum database | Each database is either an auto-vacuum database or a non auto-vacuum database. Auto-vacuum databases feature pointer-map pages (section 2.5) and have a non-zero value stored as a 4-byte big-endian integer at offset 52 of the database header (section 2.2.1). |
| B-Tree | A B-Tree is a tree structure optimized for offline storage. The table and index data in an SQLite database file is stored in B-Tree structures. |
| B-Tree cell | Each database page that is part of a B-Tree structure contains zero or more B-Tree cells. A B-Tree cell contains a single B-Tree key value (either an integer or database record) and optionally an associated database record value. |
| B-Tree page | A database page that is part of a B-Tree tree structure (not an overflow page). |
| (B-Tree) page header | The 8-byte (leaf pages) or 12-byte (internal node pages) header that occurs at the start of each B-Tree page. |
| Cell content area | The area within a B-Tree page in which the B-Tree cells are stored. |
| (Database) text encoding | The text encoding used for all text values in the database file. One of UTF-8, big-endian UTF-16 and little-endian UTF-16. The database text encoding is defined by a 4 byte field stored at byte offset 56 of the database header (see section 2.2.1). |
| Database header | The first 100 bytes of an SQLite database image constitute the database header. See section 2.2.1 for details. |
| (Database) page size | An SQLite database file is divided into one or more pages of page-size bytes each. |
| Database record | A database record is a blob of data containing the serialized representation of an ordered list of one or more SQL values. |
| Database record header | The first part of each database record contains the database record header. It encodes the types and lengths of values stored in the record (see section 2.3.2). |
| Database record data area | Following the database record header in each database record is the database record data area. It contains the actual data (string content, numeric value etc.) of all values in the record (see section 2.3.2). |
| Default pager cache size | A 32-bit integer field stored at byte offset 48 of the database file header (see section 2.2.1). |
| (Database) usable page size | The number of bytes of each database page that is usable. This is the page-size less the number of bytes left unused at the end of each page. The number of bytes left unused is governed by the value stored at offset 20 of the database header (see section 2.2.1). |
| File format read version | Single byte field stored at byte offset 20 of the database header (see section 2.2.1). |
| File format write version | Single byte field stored at byte offset 19 of the database header (see section 2.2.1). |
| File change counter | A 32-bit integer field stored at byte offset 24 of the database file header (see section 2.2.1). Normally, SQLite increments this value each time it commits a transaction. |
| Fragment | A block of 3 or less bytes of unused space within the cell content area of a B-Tree page. |
| Free block | A block of 4 or more bytes of unused space within the cell content area of a B-Tree page. |
| Free block list | The linked list of all free blocks on a single B-Tree page (see section 2.3.3.3). |
| Free page | A page that is not currently being used to store any database data or meta data. Part of the free-page list. |
| Free page list | A data structure within an SQLite database file that links all the free-pages together. |
| Index B-Tree | One of two variants on the B-Tree data structure used within SQLite database files. An index B-Tree (section 2.3.3) uses database records as keys. |
| Incremental Vacuum flag | A 32-bit integer field stored at byte offset 64 of the database file header (see section 2.2.1). In auto-vacuum databases, if this field is non-zero then the database is not automatically compacted at the end of each transaction. |
| Locking page | The database page that begins at the 1GB (230 byte) boundary. This page is always left unused. |
| Logical database | An SQLite database file is a serialized representation of a logical database. A logical database consists of the SQL database schema, the content of the various tables in the database, and assorted database properties that may be set by the user (auto-vacuum, page-size, user-cookie value etc.), |
| Non-auto-vacuum database | Any database that is not an auto-vacuum database. A non-auto-vacuum database contains no pointer-map pages and has a zero value stored in the 4-byte big-endian integer field at offset 52 of the database database header (section 2.2.1). |
| Overflow chain | A linked list of overflow pages across which a single (large) database record is stored (see section 2.3.5). |
| Overflow page | If a B-Tree cell is too large to store within a B-Tree page, a portion of it is stored using a chain of one or more overflow pages (see section 2.3.5). |
| Pointer-map page | A database page used to store meta data only present in auto-vacuum databases (see section 2.5). |
| Right child page | Each internal B-Tree node page has one or more child pages. The rightmost of these (the one containing the largest key values) is known as the right child page. |
| Root page | A root page is a database page used to store the root node of a B-Tree data structure. |
| Schema layer file format | An integer between 1 and 4 stored as a 4 byte big-endian integer at offset 44 of the database header (section 2.2.1). Certain file format constructions may only be present in databases with a certain minimum schema layer file format value. |
| Schema table | The table B-Tree with root-page 1 used to store database records describing the database schema. Accessible as the "sqlite_master" table from within SQLite. |
| Schema version | A 32-bit integer field stored at byte offset 40 of the database file header (see section 2.2.1). Normally, SQLite increments this value each time it modifies the database schema. |
| Table B-Tree | One of two variants on the B-Tree data structure used within SQLite database files. A table B-Tree (section 2.3.4) uses 64 bit integers as key values and stores an associated database record along with each key value. |
| User cookie | A 32-bit integer field stored at byte offset 60 of the database file header (see section 2.2.1). This value can be set and queried using the user_version PRAGMA but is not otherwise used by SQLite. |
| Variable Length Integer | A format used for storing 64-bit signed integer values in SQLite database files. Consumes between 1 and 9 bytes of space, depending on the precise value being stored. |
| Well formed database file | An SQLite database file that meets all the criteria laid out in section 2 of this document. |
| Database image | A serialized blob of data representing an SQLite database. The contents of a database file are usually a valid database image. |
| Database file | A database file is a file on disk that usually, but not always, contains a well-formed database image. |
| Journal file | For each database file, there may exist an associated journal file stored in the same file-system directory. Under some circumstances, the database image may be distributed between the database and journal files (instead of being stored wholly within the database file). |
| Page size | An SQLite database image is divided into fixed size pages, each "page size" bytes in size. |
| Sector size | In this document, the term "sector size" refers to a field in a journal header which determines some aspects of the layout of the journal file. It is set by SQLite (or a compatible) application based on the properties of the underlying file-system that the journal file is being written to. |
| Journal Section | A journal file may contain multiple journal sections. A journal section consists of a journal header followed by zero or more journal records. |
| Journal Header | A journal header is a control block sector-size bytes in size that appears at the start of each journal section within a journal file. |
| Journal Record | A journal record is a structure used to store data for a single database page within a journal file. A single journal file may contain many journal records. |
| Master Journal Pointer | A master journal pointer is a structure that may appear at the end of a journal file. It contains a full file-system path identifying a master-journal file. |
| Database File-System Representation | A file or files within the file-system used to store an SQLite database image. |
| Database user-cookie | An SQLite database contains a single 32-bit signed integer field known as the database user-cookie. Applications may read and write this field for any purpose. |
2 Database Image Format Details
This section describes the various fields and sub-structures that make up the format used by SQLite to serialize a logical SQL database. A serialized logical database is referred to as a database image. Section 3 describes the way a database image is stored in the file-system. Most of the time a database image is stored in a single file, the database file. So while reading this section, the term database image may be understood to mean "contents of the database file". However, it is important to remember that there are exceptions to this.
This section does not contain requirements governing the behaviour of any software system. Instead, along with the plain language description of the file format are a series of succinct, testable statements describing the properties of "well-formed SQLite database files". Some of these statements describe the contents of the database file in terms of the contents of the logical SQL database that it is a serialization of. e.g. "For each SQL table in the database, the database file shall...". The contents of a logical database consist of:
- The database schema: The set of database tables, virtual tables, indexes, triggers and views stored in the database.
- The database contents: The set of tuples (rows) stored in each database table.
- Other database properties, as follows:
- The page-size of the database.
- The text-encoding of the database.
- A flag indicating whether or not the database is an auto-vacuum database.
- The value of the database user-cookie.
- If the database is an auto-vacuum database, a flag indicating whether or not the database is in incremental vacuum mode or not.
- The default page cache size in pages to use with the database (an integer field).
Of the six database properties enumerated above, the values taken by the initial three dramatically affect the structure of the database image. Any software system that handles SQLite database images will need to understand and interpret them. Properties 4 to 6 may be considered advisory. Although properties 5 and 6 modify the operation of the SQLite library in well-defined manners, an alternative SQLite database client is free to interpret them differently, or not interpret them at all.
The concept of a logical database and its contents should be defined properly in some requirements document so that it can be referenced from here and other places. The definition will be something like the list of bullet points above.
Many of the numbered requirements in the following sub-sections describe the relationship between the contents of the logical database, as itemized above, and the contents of the serialized database image. Others describe the relationships between various database image substructures, invariants that are true for all well-formed database images.
A well-formed SQLite database image is defined as an image for which all of the statements itemized as requirements within this section are true. mention the requirements numbering scheme here. A software system that wishes to inter-operate with other systems using the SQLite database image format should only ever output well-formed SQLite databases. In the case of SQLite itself, the system should ensure that the database file contains a well-formed database image the conclusion of each transaction.
2.1 Image Format Overview
A B-Tree is a data structure designed for offline storage of a set of unique key values. It is structured so as to support fast querying for a single key or range of keys. As implemented in SQLite, each entry may be associated with a blob of data that is not part of the key. For the canonical introduction to the B-Tree and its variants, refer to reference [1]. The B-Tree implementation in SQLite also adopts some of the enhancements suggested in [2].
An SQLite database image contains one or more B-Tree structures. Each B-Tree structure stores the data for a single database table or index. Hence each database file contains a single B-Tree to store the contents of the sqlite_master table, and one B-Tree for each database table or index created by the user. If the database uses auto-increment integer primary keys, then the database file also contains a B-Tree to store the contents of the automatically created sqlite_sequence table.
SQLite uses two distinct variants of the B-Tree structure. One variant, hereafter referred to as a "table B-Tree" uses signed 64-bit integer values as keys. Each entry has an associated variable length blob of data used to store a database record (see section 2.3.2). Each SQLite database file contains one table B-Tree for the schema table and one table B-Tree for each additional database table created by the user. If it is present, the sqlite_sequence table is also stored as a table B-Tree.
A database record is a blob of data containing an ordered list of SQL values (integers, real numbers, NULL values, blobs or strings). For each row in each table in the logical database, there is an entry in the corresponding table B-Tree structure in the database image. The entry's integer key value is same as the SQL "rowid" or "integer primary key" field of the table row. The associated database record is made up of the row's column values, in declaration (CREATE TABLE) order.
The other B-Tree variant used by SQLite, hereafter an "index B-Tree" uses database records (section 2.3.2) as keys. For this kind of B-Tree, there is no additional data associated with each entry. SQLite databases contain an index B-Tree for each database index created by the user. Database indexes may be created by CREATE INDEX statements, or by UNIQUE or PRIMARY KEY (but not INTEGER PRIMARY KEY) clauses added to CREATE TABLE statements.
Index B-Tree structures contain one entry for each row in the associated table in the logical SQL database. The database record used as the key consists of the row's value for each of the indexed columns in declaration (CREATE INDEX) order, followed by the row's "rowid" or "integer primary key" column value.
For example, the following SQL script:
CREATE TABLE t1(a INTEGER PRIMARY KEY, b, c, d);
CREATE INDEX i1 ON t1(d, c);
INSERT INTO t1 VALUES(1, 'triangle', 3, 180, 'green');
INSERT INTO t1 VALUES(2, 'square', 4, 360, 'gold');
INSERT INTO t1 VALUES(3, 'pentagon', 5, 540, 'grey');
...
Creates a database image containing three B-Tree structures: one table B-Tree to store the sqlite_master table, one table B-Tree to store table "t1", and one index B-Tree to store index "i1". The B-Tree structures created for the user table and index are populated as shown in figure 1.

Figure 1 - Example B-Tree Data
The following sections and sub-sections describe precisely the format used to serialize the B-Tree structures within an SQLite database image.
2.2 Global Structure
2.2.1 Database Header
An SQLite database image begins with a 100-byte database header. The database header consists of a well known 16-byte sequence followed by a series of 1, 2 and 4 byte unsigned integers. All integers in the database header (as well as the rest of the database file) are stored in big-endian format.
The well known 16-byte sequence that begins every SQLite database file is:
0x53 0x51 0x4c 0x69 0x74 0x65 0x20 0x66 0x6f 0x72 0x6d 0x61 0x74 0x20 0x33 0x00
Interpreted as UTF-8 encoded text, this byte sequence corresponds to the string "SQLite format 3" followed by a nul-terminator byte.
The first 16 bytes of a well-formed database file shall contain the UTF-8 encoding of the string "SQLite format 3" followed by a single nul-terminator byte.
The 1, 2 and 4 byte unsigned integers that make up the rest of the database header are described in the following table.
| Byte Range | Byte Size | Description | Reqs |
|---|---|---|---|
| 16..17 | 2 | Database page size in bytes. See section 2.2.2 for details. | H30190 |
| 18 | 1 |
File-format "write version". Currently, this field is always set to 1. If a value greater than 1 is read by SQLite, then the library will only open the file for read-only access. This field and the next one are intended to be used for forwards compatibility, should the need ever arise. If in the future a version of SQLite is created that uses a file format that may be safely read but not written by older versions of SQLite, then this field will be set to a value greater than 1 to prevent older SQLite versions from writing to a file that uses the new format. | H30040 |
| 19 | 1 |
File-format "read version". Currently, this field is always set to 1. If a value greater than 1 is read by SQLite, then the library will refuse to open the database Like the "write version" described above, this field exists to facilitate some degree of forwards compatibility, in case it is ever required. If a version of SQLite created in the future uses a file format that may not be safely read by older SQLite versions, then this field will be set to a value greater than 1. | H30040 |
| 20 | 1 | Number of bytes of unused space at the end of each database page. Usually this field is set to 0. If it is non-zero, then it contains the number of bytes that are left unused at the end of every database page (see section 2.2.2 for a description of a database page). | H30040 |
| 21 | 1 | Maximum fraction of an index tree page to use for embedded content. This value is used to determine the maximum size of a B-Tree cell to store as embedded content on a page that is part of an index B-Tree. Refer to section 2.3.3.4 for details. | H30040 |
| 22 | 1 | Minimum fraction of an index B-Tree page to use for embedded content when an entry uses one or more overflow pages. This value is used to determine the portion of a B-Tree cell that requires one or more overflow pages to store as embedded content on a page that is part of an index B-Tree. Refer to section 2.3.3.4 for details. | H30040 |
| 23 | 1 | Minimum fraction of an table B-Tree leaf page to use for embedded content when an entry uses one or more overflow pages. This value is used to determine the portion of a B-Tree cell that requires one or more overflow pages to store as embedded content on a page that is a leaf of a table B-Tree. Refer to section 2.3.4.3 for details. | H30040 |
| 24..27 | 4 |
The file change counter. Each time a database transaction is committed, the value of the 32-bit unsigned integer stored in this field is incremented. SQLite uses this field to test the validity of its internal cache. After unlocking the database file, SQLite may retain a portion of the file cached in memory. However, since the file is unlocked, another process may use SQLite to modify the contents of the file, invalidating the internal cache of the first process. When the file is relocked, the first process can check if the value of the file change counter has been modified since the file was unlocked. If it has not, then the internal cache may be assumed to be valid and may be reused. | H33040 |
| 28..31 | 4 |
The in-header database size. This field holds the logical size of the database file in pages. This field is only valid if it is nonzero and if the file change counter at offset 24 exactly matches the version-valid-for at offset 92. The in-header database size will only be valid when the database was last written by SQLite version 3.7.0 or later. If the in-header database size is valid, then it is used as the logical size of the database. If the in-header database size is not valid, then the actual database file size is examined to determine the logical database size. | |
| 32..35 | 4 | Page number of first freelist trunk page. For more details, refer to section 2.4. | H31320 |
| 36..39 | 4 | Number of free pages in the database file. For more details, refer to section 2.4. | H31310 |
| 40..43 | 4 | The schema version. Each time the database schema is modified (by creating or deleting a database table, index, trigger or view) the value of the 32-bit unsigned integer stored in this field is incremented. | H33050 |
| 44..47 | 4 |
Schema layer file-format. This value is similar to the "read-version" and "write-version" fields at offsets 18 and 19 of the database header. If SQLite encounters a database with a schema layer file-format value greater than the file-format that it understands (currently 4), then SQLite will refuse to access the database. Usually, this value is set to 1. However, if any of the following file-format features are used, then the schema layer file-format must be set to the corresponding value or greater:
Turns out SQLite can be tricked into violating this. If you delete all tables from a database and then VACUUM the database, the schema layer file-format field somehow gets set to 0. | H30120 |
| 48..51 | 4 | Default pager cache size. This field is used by SQLite to store the recommended pager cache size to use for the database. | H30130 |
| 52..55 | 4 | For auto-vacuum capable databases, the numerically largest root-page number in the database. Since page 1 is always the root-page of the schema table (section 2.2.3), this value is always non-zero for auto-vacuum databases. For non-auto-vacuum databases, this value is always zero. | H30140, H30141 |
| 56..59 | 4 | (constant) Database text encoding. A value of 1 means all text values are stored using UTF-8 encoding. 2 indicates little-endian UTF-16 text. A value of 3 means that the database contains big-endian UTF-16 text. | H30150 |
| 60..63 | 4 | The user-cookie value. A 32-bit integer value available to the user for read/write access. | H30160 |
| 64..67 | 4 | The incremental-vacuum flag. In non-auto-vacuum databases this value is always zero. In auto-vacuum databases, this field is set to 1 if "incremental vacuum" mode is enabled. If incremental vacuum mode is not enabled, then the database file is reorganized so that it contains no free pages (section 2.4) at the end of each database transaction. If incremental vacuum mode is enabled, then the reorganization is not performed until explicitly requested by the user. | H30171 |
| 92..95 | 4 | The version-valid-for integer. This is a copy of the file change counter (offset 24) for when the SQLite version number in offset 96 was written. This integer is also used to determine if the in-header database size (offset 28) is valid. | |
| 99..99 | 4 | The SQLite version number (obtained from SQLITE_VERSION_NUMBER) for the instance of SQLite that last wrote to the database file. Only SQLite versions 3.7.0 and later will update this number. |
The four byte block beginning at offset 28 stores a big-endian integer which is the number of pages in the database. Older versions of SQLite set this integer to zero. For compatibility, SQLite database readers should be able to deal with either value.
The 32 byte block beginning at offset 68 is unused in SQLite versions up to and including 3.6.23.1. The 8 bytes at offset 92 came into use beginning with SQLite version 3.7.0. The 24 bytes between offset 68 and offset 91 might come into use in a future release of SQLite.
The following requirements state that certain database header fields must contain defined constant values, even though the sqlite database file format is designed to allow various values. These fields were intended to be flexible when the SQLite database image format was designed, but it has since been determined that it is faster and safer to require these parameters to be populated with well-known values. Specifically, in a well-formed database, the following header fields are always set to well-known values:
- The file-format write version (single byte field, byte offset 18), is always set to 0x01.
- The file-format read version (single byte field, byte offset 19), is always set to 0x01.
- The number of unused bytes on each page (single byte field, byte offset 20), is always set to 0x00.
- The maximum fraction of an index B-Tree page to use for embedded content (single byte field, byte offset 21), is always set to 0x40.
- The minimum fraction of an index B-Tree page to use for embedded content when using overflow pages (single byte field, byte offset 22), is always set to 0x20.
- The minimum fraction of a table B-Tree page to use for embedded content when using overflow pages (single byte field, byte offset 23), is always set to 0x20.
The following requirement encompasses all of the above.
The 6 bytes beginning at byte offset 18 of a well-formed database image shall contain the values 0x01, 0x01, 0x00, 0x40, 0x20 and 0x20, respectively.
Section 2 identifies six persistent user-visible properties of an SQLite database. The following requirements describe the way in which these properties are stored.
The 2-byte big-endian unsigned integer field at byte offset 16 of a well-formed database image shall be set to the value of the database page-size.
The page-size of an SQLite database in bytes shall be an integer power of 2 between 512 and 32768, inclusive.
The 4 byte big-endian unsigned integer field at byte offset 56 of a well-formed database image shall be set to 1 if the database text-encoding is UTF-8, 2 if the database text-encoding is little-endian UTF-16, and 3 if the database text-encoding is big-endian UTF-16.
If the database is not an auto-vacuum capable database, then the 4 byte big-endian unsigned integer field at byte offset 52 of a well-formed database image shall contain the value 0.
If the database is an auto-vacuum capable database, then the 4 byte big-endian unsigned integer field at byte offset 52 of a well-formed database image shall contain the numerically largest root-page number of any table or index B-Tree within the database image.
The 4-byte big-endian unsigned integer field at byte offset 60 of a well-formed database image shall be set to the value of the database user-cookie.
The 4-byte big-endian unsigned integer field at byte offset 64 of a well-formed database image shall be set to the value of the database incremental-vacuum flag.
The value of the incremental-vacuum flag of an SQLite database shall be either 0 or 1.
The 4-byte big-endian unsigned integer field at byte offset 48 of a well-formed database image shall be set to the value of the database default page-cache size.
The following requirement describes the valid range of values for the schema layer file format field.
The 4-byte big-endian signed integer field at byte offset 44 of a well-formed database image, the schema layer file format field, shall be set to an integer value between 1 and 4, inclusive.
See the note to do with the schema file format version above. Turns out this field may also be set to 0 by SQLite.
2.2.2 Pages and Page Types
The entire database file is divided into pages, each page consisting of page-size bytes, where page-size is the 2-byte integer value stored at offset 16 of the database header (see above). The page-size is always a power of two between 512 (29) and 32768 (215) or the value 1 used to represent a 65536-byte page. This field can equivalently be viewed as a little-endian number which is page size divided by 256. SQLite database files always consist of an exact number of pages.
Pages are numbered beginning from 1, not 0. Page 1 consists of the first page-size bytes of the database file. The database header described in the previous section consumes the first 100 bytes of page 1.
Each page of the database file is one of the following:
- A B-Tree page. B-Tree pages are part of the tree structures used to store database tables and indexes.
- An overflow page. Overflow pages are used by particularly large database records that do not fit on a single B-Tree page.
- A free page. Free pages are pages within the database file that are not being used to store meaningful data.
- A "pointer-map" page. In auto-vacuum capable databases (databases for which the 4 byte big-endian integer stored at byte offset 52 of the database header is non-zero) some pages are permanently designated "pointer-map" pages. See section 2.5 for details.
- The locking page. The database page that starts at byte offset 230, if it is large enough to contain such a page, is always left unused.
The size of a well formed database image shall be an integer multiple of the database page size.
Each page of a well formed database image shall be exactly one of a B-Tree page, an overflow page, a free page, a pointer-map page or the locking page.
The database page that starts at byte offset 230, the locking page, shall never be used for any purpose.
2.2.3 The Schema Table
Apart from being the page that contains the file-header, page 1 of a database image is special because it is the root page of the B-Tree structure that contains the schema table data. From the SQL level, the schema table is accessible via the name "sqlite_master".
The exact format of the B-Tree structure and the meaning of the term "root page" is discussed in section 2.3. For now, it is sufficient to know that the B-Tree structure is a data structure that stores a set of records. Each record is an ordered set of SQL values (the format of which is described in section 2.3.2). Given the root page number of the B-Tree structure (which is well known for the schema table), it is possible to iterate through the set of records.
The schema table contains a record for each SQL table (including virtual tables) except for sqlite_master, and for each index, trigger and view in the logical database. There is also an entry for each UNIQUE or PRIMARY KEY clause present in the definition of a database table. Each record in the schema table contains exactly 5 values, in the following order:
| Field | Description |
|---|---|
| Schema item type. | A string value. One of "table", "index", "trigger" or "view", according to the schema item type. Entries associated with UNIQUE or PRIMARY KEY clauses have this field set to "index". |
| Schema item name. | A string value. The name of the database schema item (table, index, trigger or view) associated with this record, if any. Entries associated with UNIQUE or PRIMARY KEY clauses have this field set to a string of the form "sqlite_autoindex_<name>_<idx>" where <name> is the name of the SQL table and <idx> is an integer value. |
| Associated table name. | A string value. For "table" or "view" records this is a copy of the second (previous) value. For "index" and "trigger" records, this field is set to the name of the associated database table. |
| The "root page" number. | For "trigger" and "view" records, as well as "table" records associated with virtual tables, this is set to integer value 0. For other "table" and "index" records (including those associated with UNIQUE or PRIMARY KEY clauses), this field contains the root page number (an integer) of the B-Tree structure that contains the table or index data. |
| The SQL statement. | A string value. The SQL statement used to create the schema item (i.e. the complete text of an SQL "CREATE TABLE" statement). This field contains an empty string for table entries associated with PRIMARY KEY or UNIQUE clauses. Refer to some document that describes these SQL statements more precisely. |
Logical database schema items other than non-virtual tables and indexes (including indexes created by UNIQUE or PRIMARY key constraints) do not require any other data structures to be created within the database file.
Tables and indexes on the other hand, are represented within the database file by both an entry in the schema table and a B-Tree structure stored elsewhere in the file. The specific B-Tree associated with each database table or index is identified by its root page number, which is stored in the 4th field of the schema table record. In a non-auto-vacuum database, the B-Tree root pages may be stored anywhere within the database file. For an auto-vacuum database, all B-Tree root pages must at all times form a contiguous set starting at page 3 of the database file, skipping any pages that are required to be used as pointer-map pages (see section 2.5).
As noted in section 2.2.1, in an auto-vacuum database the page number of the page immediately following the final root page in the contiguous set of root pages is stored as a 4 byte big-endian integer at byte offset 52 of the database header. Unless that page is itself a pointer-map page, in which case the page number of the page following it is stored instead.
For example, if the schema of a logical database is created using the following SQL statements:
CREATE TABLE abc(a, b, c);
CREATE INDEX i1 ON abc(b, c);
CREATE TABLE main.def(a PRIMARY KEY, b, c, UNIQUE(b, c));
CREATE VIEW v1 AS SELECT * FROM abc;
Then the schema table would contain a total of 7 records, as follows:
| Field 1 | Field 2 | Field 3 | Field 4 | Field 5 |
|---|---|---|---|---|
| table | abc | abc | 2 | CREATE TABLE abc(a, b, c) |
| index | i1 | abc | 3 | CREATE INDEX i1 ON abc(b, c) |
| table | def | def | 4 | CREATE TABLE def(a PRIMARY KEY, b, c, UNIQUE(b, c)) |
| index | sqlite_autoindex_def_1 | def | 5 | |
| index | sqlite_autoindex_def_2 | def | 6 | |
| view | v1 | v1 | 0 | CREATE VIEW v1 AS SELECT * FROM abc |
In a well-formed database file, the portion of the first database page not consumed by the database file-header (all but the first 100 bytes) contains the root node of a table B-Tree, the schema table.
All records stored in the schema table contain exactly five fields.
The following requirements describe "table" records.
For each SQL table in the database apart from itself ("sqlite_master"), the schema table of a well-formed database file contains an associated record.
The first field of each schema table record associated with an SQL table shall be the text value "table".
The second field of each schema table record associated with an SQL table shall be a text value set to the name of the SQL table.
In a well-formed database file, the third field of all schema table records associated with SQL tables shall contain the same value as the second field.
In a well-formed database file, the fourth field of all schema table records associated with SQL tables that are not virtual tables contains the page number (an integer value) of the root page of the associated table B-Tree structure within the database file.
If the associated database table is a virtual table, the fourth field of the schema table record shall contain the integer value 0 (zero).
In a well-formed database, the fifth field of all schema table records associated with SQL tables shall contain a "CREATE TABLE" or "CREATE VIRTUAL TABLE" statement (a text value). The details of the statement shall be such that executing the statement would create a table of precisely the same name and schema as the existing database table.
The following requirements describe "implicit index" records.
For each PRIMARY KEY or UNIQUE constraint present in the definition of each SQL table in the database, the schema table of a well-formed database shall contain a record with the first field set to the text value "index", and the second field set to a text value containing a string of the form "sqlite_autoindex_<name>_<idx>", where <name> is the name of the SQL table and <idx> is an integer value.
In a well-formed database, the third field of all schema table records associated with SQL PRIMARY KEY or UNIQUE constraints shall contain the name of the table to which the constraint applies (a text value).
In a well-formed database, the fourth field of all schema table records associated with SQL PRIMARY KEY or UNIQUE constraints shall contain the page number (an integer value) of the root page of the associated index B-Tree structure.
In a well-formed database, the fifth field of all schema table records associated with SQL PRIMARY KEY or UNIQUE constraints shall contain an SQL NULL value.
The following requirements describe "explicit index" records.
For each SQL index in the database, the schema table of a well-formed database shall contain a record with the first field set to the text value "index" and the second field set to a text value containing the name of the SQL index.
In a well-formed database, the third field of all schema table records associated with SQL indexes shall contain the name of the SQL table that the index applies to.
In a well-formed database, the fourth field of all schema table records associated with SQL indexes shall contain the page number (an integer value) of the root page of the associated index B-Tree structure.
In a well-formed database, the fifth field of all schema table records associated with SQL indexes shall contain an SQL "CREATE INDEX" statement (a text value). The details of the statement shall be such that executing the statement would create an index of precisely the same name and content as the existing database index.
The following requirements describe "view" records.
For each SQL view in the database, the schema table of a well-formed database shall contain a record with the first field set to the text value "view" and the second field set to a text value containing the name of the SQL view.
In a well-formed database, the third field of all schema table records associated with SQL views shall contain the same value as the second field.
In a well-formed database, the third field of all schema table records associated with SQL views shall contain the integer value 0.
In a well-formed database, the fifth field of all schema table records associated with SQL indexes shall contain an SQL "CREATE VIEW" statement (a text value). The details of the statement shall be such that executing the statement would create a view of precisely the same name and definition as the existing database view.
The following requirements describe "trigger" records.
For each SQL trigger in the database, the schema table of a well-formed database shall contain a record with the first field set to the text value "trigger" and the second field set to a text value containing the name of the SQL trigger.
In a well-formed database, the third field of all schema table records associated with SQL triggers shall contain the name of the database table or view to which the trigger applies.
In a well-formed database, the third field of all schema table records associated with SQL triggers shall contain the integer value 0.
In a well-formed database, the fifth field of all schema table records associated with SQL indexes shall contain an SQL "CREATE TRIGGER" statement (a text value). The details of the statement shall be such that executing the statement would create a trigger of precisely the same name and definition as the existing database trigger.
The following requirements describe the placement of B-Tree root pages in auto-vacuum databases.
In an auto-vacuum database, all pages that occur before the page number stored in the auto-vacuum last root-page field of the database file header (see H30140) must be either B-Tree root pages, pointer-map pages or the locking page.
In an auto-vacuum database, no B-Tree root pages may occur on or after the page number stored in the auto-vacuum last root-page field of the database file header (see H30140) must be either B-Tree root pages, pointer-map pages or the locking page.
2.3 B-Tree Structures
A large part of any SQLite database file is given over to one or more B-Tree structures. A single B-Tree structure is stored using one or more database pages. Each page contains a single B-Tree node. The pages used to store a single B-Tree structure need not form a contiguous block. The page that contains the root node of a B-Tree structure is known as the "root page".
SQLite uses two distinct variants of the B-Tree structure:
- The table B-Tree, which uses 64-bit integer values for keys. In a table B-Tree, an associated database record (section 2.3.2) is stored along with each entry. Table B-Tree structures are described in detail in section 2.3.4.
- The index B-Tree, which uses database records as keys. Index B-Tree structures are described in detail in section 2.3.3.
As well as the schema table, a well-formed database file contains N table B-Tree structures, where N is the number of non-virtual tables in the logical database, excluding the sqlite_master table but including sqlite_sequence and other system tables.
A well-formed database file contains N table B-Tree structures, where N is the number of indexes in the logical database, including indexes created by UNIQUE or PRIMARY KEY clauses in the declaration of SQL tables.
2.3.1 Variable Length Integer Format
In several parts of the B-Tree structure, 64-bit twos-complement signed integer values are stored in the "variable length integer format" described here.
A variable length integer consumes from one to nine bytes of space, depending on the value stored. Seven bits are used from each of the first eight bytes present, and, if present, all eight from the final ninth byte. Unless the full nine byte format is used, the serialized form consists of all bytes up to and including the first byte with the 0x80 bit cleared.
The number of bytes present depends on the position of the most significant set bit in the 64-bit word. Negative numbers always have the most significant bit of the word (the sign bit) set and so are always encoded using the full nine bytes. Positive integers may be encoded using less space. The following table shows the 9 different length formats available for storing a variable length integer value.
| Bytes | Value Range | Bit Pattern |
|---|---|---|
| 1 | 7 bit | 0xxxxxxx |
| 2 | 14 bit | 1xxxxxxx 0xxxxxxx |
| 3 | 21 bit | 1xxxxxxx 1xxxxxxx 0xxxxxxx |
| 4 | 28 bit | 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx |
| 5 | 35 bit | 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx |
| 6 | 42 bit | 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx |
| 7 | 49 bit | 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx |
| 8 | 56 bit | 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx |
| 9 | 64 bit | 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx xxxxxxxx |
When using the full 9 byte representation, the first byte contains the 7 most significant bits of the 64-bit value. The final byte of the 9 byte representation contains the 8 least significant bits of the 64-bit value. When using one of the other representations, the final byte contains the 7 least significant bits of the 64-bit value. The second last byte, if present, contains the 7 next least significant bits of the value, and so on. The significant bits of the 64-bit value for which no storage is provided are assumed to be zero.
When encoding a variable length integer, SQLite usually selects the most compact representation that provides enough storage to accommodate the most significant set bit of the value. This is not required however, using more bytes than is strictly necessary when encoding an integer is valid.
| Decimal | Hexadecimal | Variable Length Integer |
|---|---|---|
| 43 | 0x000000000000002B | 0x2B |
| 200815 | 0x000000000003106F | 0x8C 0xA0 0x6F |
| -1 | 0xFFFFFFFFFFFFFFFF | 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF |
| -78506 | 0xFFFFFFFFFFFECD56 | 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFD 0xCD 0x56 |
A 64-bit signed integer value stored in variable length integer format consumes from 1 to 9 bytes of space.
The most significant bit of all bytes except the last in a serialized variable length integer is always set. Unless the serialized form consumes the maximum 9 bytes available, then the most significant bit of the final byte of the representation is always cleared.
The eight least significant bytes of the 64-bit twos-complement representation of a value stored in a 9 byte variable length integer are stored in the final byte (byte offset 8) of the serialized variable length integer. The other 56 bits are stored in the 7 least significant bits of each of the first 8 bytes of the serialized variable length integer, in order from most significant to least significant.
A variable length integer that consumes less than 9 bytes of space contains a value represented as an N-bit unsigned integer, where N is equal to the number of bytes consumed by the serial representation (between 1 and 8) multiplied by 7. The N bits are stored in the 7 least significant bits of each byte of the serial representation, from most to least significant.
2.3.2 Database Record Format
A database record is a blob of data that represents an ordered list of one or more SQL values. Database records are used in two places in SQLite database files - as the associated data for entries in table B-Tree structures, and as the key values in index B-Tree structures. The size (number of bytes consumed by) a database record depends on the values it contains.
Each database record consists of a short record header followed by a data area. The record header consists of N+1 variable length integers (see section 2.3.1), where N is the number of values stored in the record.
The first variable length integer in a record header contains the size of the record header in bytes. The following N variable length integer values each describe the type and size of the corresponding SQL value within the record (the second integer in the record header describes the first value in the record, etc.). The second and subsequent integer values in a record header are interpreted according to the following table:
| Header Value | Data type and size |
|---|---|
| 0 | An SQL NULL value (type SQLITE_NULL). This value consumes zero bytes of space in the record's data area. |
| 1 | An SQL integer value (type SQLITE_INTEGER), stored as a big-endian 1-byte signed integer. |
| 2 | An SQL integer value (type SQLITE_INTEGER), stored as a big-endian 2-byte signed integer. |
| 3 | An SQL integer value (type SQLITE_INTEGER), stored as a big-endian 3-byte signed integer. |
| 4 | An SQL integer value (type SQLITE_INTEGER), stored as a big-endian 4-byte signed integer. |
| 5 | An SQL integer value (type SQLITE_INTEGER), stored as a big-endian 6-byte signed integer. |
| 6 | An SQL integer value (type SQLITE_INTEGER), stored as an big-endian 8-byte signed integer. |
| 7 | An SQL real value (type SQLITE_FLOAT), stored as an 8-byte IEEE floating point value. |
| 8 | The literal SQL integer 0 (type SQLITE_INTEGER). The value consumes zero bytes of space in the record's data area. Values of this type are only present in databases with a schema file format (the 32-bit integer at byte offset 44 of the database header) value of 4 or greater. |
| 9 | The literal SQL integer 1 (type SQLITE_INTEGER). The value consumes zero bytes of space in the record's data area. Values of this type are only present in databases with a schema file format (the 32-bit integer at byte offset 44 of the database header) value of 4 or greater. |
| bytes * 2 + 12 | Even values greater than or equal to 12 are used to signify a blob of data (type SQLITE_BLOB) (n-12)/2 bytes in length, where n is the integer value stored in the record header. |
| bytes * 2 + 13 | Odd values greater than 12 are used to signify a string (type SQLITE_TEXT) (n-13)/2 bytes in length, where n is the integer value stored in the record header. |
Immediately following the record header is the data for each of the record's values. A record containing N values is depicted in figure 2.
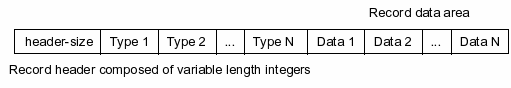
Figure 2 - Database Record Format
For each SQL value in the record, there is a blob of data stored in the records data area. If the corresponding integer type value in the record header is 0 (NULL), 8 (integer value 0) or 9 (integer value 1), then the blob of data is zero bytes in length. Otherwise, the length of the data field is as described in the table above.
The data field associated with a string value contains the string encoded using the database encoding, as defined in the database header (see section 2.2.1). No nul-terminator character is stored in the database.
A database record consists of a database record header, followed by database record data. The first part of the database record header is a variable length integer containing the total size (including itself) of the header in bytes.
Following the length field, the remainder of the database record header is populated with N variable length integer fields, where N is the number of database values stored in the record.
Following the database record header, the database record data is made up of N variable length blobs of data, where N is again the number of database values stored in the record. The n blob contains the data for the nth value in the database record. The size and format of each blob of data is encoded in the corresponding variable length integer field in the database record header.
A value of 0 stored within the database record header indicates that the corresponding database value is an SQL NULL. In this case the blob of data in the data area is 0 bytes in size.
A value of 1 stored within the database record header indicates that the corresponding database value is an SQL integer. In this case the blob of data contains the integer value, formatted as a 1-byte big-endian signed integer.
A value of 2 stored within the database record header indicates that the corresponding database value is an SQL integer. In this case the blob of data contains the integer value, formatted as a 2-byte big-endian signed integer.
A value of 3 stored within the database record header indicates that the corresponding database value is an SQL integer. In this case the blob of data contains the integer value, formatted as a 3-byte big-endian signed integer.
A value of 4 stored within the database record header indicates that the corresponding database value is an SQL integer. In this case the blob of data contains the integer value, formatted as a 4-byte big-endian signed integer.
A value of 5 stored within the database record header indicates that the corresponding database value is an SQL integer. In this case the blob of data contains the integer value, formatted as a 6-byte big-endian signed integer.
A value of 6 stored within the database record header indicates that the corresponding database value is an SQL integer. In this case the blob of data contains the integer value, formatted as a 8-byte big-endian signed integer.
A value of 7 stored within the database record header indicates that the corresponding database value is an SQL real (floating point number). In this case the blob of data contains an 8-byte IEEE floating point number, stored in big-endian byte order.
A value of 8 stored within the database record header indicates that the corresponding database value is an SQL integer, value 0. In this case the blob of data in the data area is 0 bytes in size.
A value of 9 stored within the database record header indicates that the corresponding database value is an SQL integer, value 1. In this case the blob of data in the data area is 0 bytes in size.
An even value greater than or equal to 12 stored within the database record header indicates that the corresponding database value is an SQL blob field. The blob of data contains the value data. The blob of data is exactly (n-12)/2 bytes in size, where n is the integer value stored in the database record header.
An odd value greater than or equal to 13 stored within the database record header indicates that the corresponding database value is an SQL text field. The blob of data contains the value text stored using the database encoding, with no nul-terminator. The blob of data is exactly (n-12)/2 bytes in size, where n is the integer value stored in the database record header.
The following database file properties define restrictions on the integer values that may be stored within a database record header.
In a well-formed database file, if the values 8 or 9 appear within any database record header within the database, then the schema-layer file format (stored at byte offset 44 of the database file header) must be set to 4.
In a well-formed database file, the values 10 and 11, and all negative values may not appear within any database record header in the database.
2.3.3 Index B-Trees
As specified in section 2.1, index B-Tree structures store a unique set of the database records described in the previous section. While in some cases, when there are very few entries in the B-Tree, the entire structure may fit on a single database page, usually the database records must be spread across two or more pages. In this case, the pages are organized into a tree structure with a single "root" page at the head of the tree.
Within the tree structure, each page is either an internal tree node containing an ordered list of N references to child nodes (page numbers) and N-1 database records, or a leaf node containing M database records. The value of N may be different for each page, but is always two or greater. Similarly, each leaf page may have a different non-zero positive value for M. The tree is always of uniform height, meaning the number of intermediate levels between each leaf node page and the root page is the same.
Within both internal and leaf node pages, the records are stored in sorted order. The comparison function used to determine the sort order is described in section 2.3.3.2.
Records are distributed throughout the tree such that for each internal node, all records stored in the sub-tree headed by the first child node ( C(0) ) are considered less than the first record stored on the internal node ( R(0) ) by the comparison function described in section 2.3.3.2. Similarly all records stored in the sub-tree headed by C(n) are considered greater than R(n-1) but less than R(n) for values of n between 1 and N-2, inclusive. All records in the sub-tree headed by C(N-1) are greater than the largest record stored on the internal node.
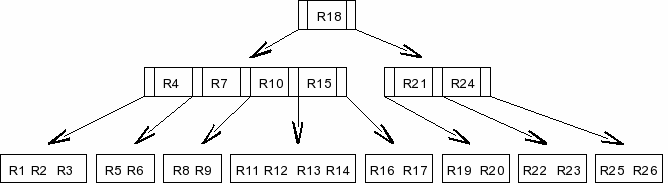
Figure 3 - Index B-Tree Tree Structure
Figure 3 depicts one possible record distribution for an index B-Tree containing records R1 to R26, assuming that for all values of N, R(N+1)>R(N). In total the B-Tree structure uses 11 database file pages. Internal tree nodes contain database records and references to child node pages. Leaf nodes contain database records only.
The pages in an index B-Tree structures are arranged into a tree structure such that all leaf pages are at the same depth.
Each leaf node page in an index B-Tree contains one or more B-Tree cells, where each cell contains a database record.
Each internal node page in an index B-Tree contains one or more B-Tree cells, where each cell contains a child page number, C, and a database record R. All database records stored within the sub-tree headed by page C are smaller than record R, according to the index sort order (see below). Additionally, unless R is the smallest database record stored on the internal node page, all integer keys within the sub-tree headed by C are greater than R-1, where R-1 is the largest database record on the internal node page that is smaller than R.
As well as child page numbers associated with B-Tree cells, each internal node page in an index B-Tree contains the page number of an extra child page, the right-child page. All database records stored in all B-Tree cells within the sub-tree headed by the right-child page are greater than all database records stored within B-Tree cells on the internal node page.
The precise way in which index B-Tree pages and cells are formatted is described in subsequent sections.
2.3.3.1 Index B-Tree Content
The database file contains one index B-Tree for each database index in the logical database, including those created by UNIQUE or PRIMARY KEY clauses in table declarations. Each record stored in an index B-Tree contains the same number of fields, the number of indexed columns in the database index declaration plus one.
An index B-Tree contains an entry for each row in its associated database table. The fields of the record used as the index B-Tree key are copies of each of the indexed columns of the associated database row, in order, followed by the rowid value of the same row. See figure 1 for an example.
In a well-formed database, each index B-Tree contains a single entry for each row in the indexed logical database table.
Each database record (key) stored by an index B-Tree in a well-formed database contains the same number of values, the number of indexed columns plus one.
The final value in each database record (key) stored by an index B-Tree in a well-formed database contains the rowid (an integer value) of the corresponding logical database row.
The first N values in each database record (key) stored in an index B-Tree where N is the number of indexed columns, contain the values of the indexed columns from the corresponding logical database row, in the order specified for the index.
2.3.3.2 Record Sort Order
This section defines the comparison function used when database records are used as B-Tree keys for index B-Trees. The comparison function is only defined when both database records contain the same number of fields.
When comparing two database records, the first field of one record is compared to the first field of the other. If they are not equal, the next pair of fields are compared, and so on. If all the fields in the database records are equal, then the two records are considered equal. Otherwise, the result of the comparison is determined by the first pair of inequal fields.
Two database record fields (SQL values) are compared using the following rules:
- If both values are NULL, then they are considered equal.
- If one value is a NULL and the other is not, it is considered the lesser of the two.
- If both values are either real or integer values, then the comparison is done numerically.
- If one value is a real or integer value, and the other is a text or blob value, then the numeric value is considered lesser.
- If both values are text, then the collation function is used to compare them. The collation function is a property of the index column in which the values are found. Link to document with CREATE INDEX syntax.
- If one value is text and the other a blob, the text value is considered lesser.
- If both values are blobs, memcmp() is used to determine the results of the comparison function. If one blob is a prefix of the other, the shorter blob is considered lesser.
Each column of a database index may be declared as "descending". Link to document with CREATE INDEX syntax. In SQLite database files with a schema layer file-format equal to 4, this modifies the order in which the records are stored in the corresponding index B-Tree structure. For each index column declared as descending, the results of the above comparison procedure are inverted.
The columns of database indexes created by UNIQUE or PRIMARY KEY clauses are never treated as descending.
Need requirements style statements for this information. Easier to do once collation sequences have been defined somewhere.
2.3.3.3 Index B-Tree Page Format
Each index B-Tree page is divided into four sections that occur in order on the page:
- The 8-byte (leaf node pages) or 12-byte (internal tree node pages) page-header.
- The cell offset array. This is a series of N big-endian 2-byte integer values, where N is the number of records stored on the page.
- A block of unused space. This may be 0 bytes in size.
- The cell content area consumes the remaining space on the page.

Figure 4 - Index B-Tree Page Data
The 8-byte (leaf node pages) or 12-byte (internal tree node pages) page header that begins each index B-Tree page is made up of a series of 1, 2 and 4 byte unsigned integer values as shown in the following table. All values are stored in big-endian byte order.
| Byte Range | Byte Size | Description |
|---|---|---|
| 0 | 1 | B-Tree page flags. For an index B-Tree internal tree node page, this is set to 0x02. For a leaf node page, 0x0A. |
| 1..2 | 2 | Byte offset of first block of free space on this page. If there are no free blocks on this page, this field is set to 0. |
| 3..4 | 2 | Number of cells (entries) on this page. |
| 5..6 | 2 | Byte offset of the first byte of the cell content area (see figure 4), relative to the start of the page. If this value is zero, then it should be interpreted as 65536. |
| 7 | 1 | Number of fragmented free bytes on page. |
| 8..11 | 4 | Page number of rightmost child-page (the child-page that heads the sub-tree in which all records are larger than all records stored on this page). This field is not present for leaf node pages. |
The cell content area, which occurs last on the page, contains one B-Tree cell for each record stored on the B-Tree page. On a leaf node page, each cell is responsible for storing a database record only. On an internal tree node page, each cell contains a database record and the corresponding child page number ((R(0) and C(0)) are stored together, for example - the cell record is considered greater than all records stored in the sub-tree headed by the child page). The final child page number is stored as part of the page header.
The B-Tree cells may be distributed throughout the cell content area and may be interspersed with blocks of unused space. They are not sorted within the cell content area in any particular order. The serialized format of a B-Tree cell is described in detail in section 2.3.3.4.
The byte offset of each cell in the cell content area, relative to the start of the page, is stored in the cell offset array. The offsets are in sorted order according to the database records stored in the corresponding cells. The first offset in the array is the offset of the cell containing the smallest record on the page, according to the comparison function defined in section 2.3.3.2.
As well as the block of unused space between the cell offset array and the cell content area, which may be any size, there may be small blocks of free space interspersed with the B-Tree cells within the cell content area. These are classified into two classes, depending on their size:
- Blocks of free-space consisting of 3 bytes or less are called fragments. The total number of bytes consumed by all fragments on a page is stored in the 1 byte unsigned integer at byte offset 7 of the page header. The total number of fragmented bytes on a single page is never greater than 255.
- Blocks of free-space consisting of more than 3 bytes of contiguous space are called free blocks. All free blocks on a single page are linked together into a singly linked list. The byte offset (relative to the start of the page) of the first block in the list is stored in the 2 byte unsigned integer stored at byte offset 1 of the page header. The first two bytes of each free block contain the byte offset (again relative to the start of the page) of the next block in the list stored as a big-endian unsigned integer. The first two bytes of the final block in the list are set to zero. The third and fourth bytes of each free block contain the total size of the free block in bytes, stored as a 2 byte big-endian unsigned integer.
The list of free blocks is kept in order, sorted by offset. Right? Later: True statement. SQLite function sqlite3BtreeInitPage() returns SQLITE_CORRUPT if they are not.
The b-tree page flags field (the first byte) of each database page used as an internal node of an index B-Tree structure is set to 0x02.
The b-tree page flags field (the first byte) of each database page used as a leaf node of an index B-Tree structure is set to 0x0A.
The following requirements describe the B-Tree page header present at the start of both index and table B-Tree pages.
The first byte of each database page used as a B-Tree page contains the b-tree page flags field. On page 1, the b-tree page flags field is stored directly after the 100 byte file header at byte offset 100.
The number of B-Tree cells stored on a B-Tree page is stored as a 2-byte big-endian integer starting at byte offset 3 of the B-Tree page. On page 1, this field is stored at byte offset 103.
The 2-byte big-endian integer starting at byte offset 5 of each B-Tree page contains the byte-offset from the start of the page to the start of the cell content area, which consumes all space from this offset to the end of the usable region of the page. On page 1, this field is stored at byte offset 105. All B-Tree cells on the page are stored within the cell-content area.
On each page used as an internal node a of B-Tree structures, the page number of the rightmost child node in the B-Tree structure is stored as a 4-byte big-endian unsigned integer beginning at byte offset 8 of the database page, or byte offset 108 on page 1.
This requirement describes the cell content offset array. It applies to both B-Tree variants.
Immediately following the page header on each B-Tree page is the cell offset array, consisting of N 2-byte big-endian unsigned integers, where N is the number of cells stored on the B-Tree page (H30840). On an internal node B-Tree page, the cell offset array begins at byte offset 12, or on a leaf page, byte offset 8. For the B-Tree node on page 1, these offsets are 112 and 108, respectively.
The cell offset array and the cell content area (H30850) may not overlap.
Each value stored in the cell offset array must be greater than or equal to the offset to the cell content area (H30850), and less than the database page size.
The N values stored within the cell offset array are the byte offsets from the start of the B-Tree page to the beginning of each of the N cells stored on the page.
No two B-Tree cells may overlap.
The following requirements govern management of free-space within the page content area (both table and index B-Tree pages).
Within the cell content area, all blocks of contiguous free-space (space not used by B-Tree cells) greater than 3 bytes in size are linked together into a linked list, the free block list. Such blocks of free space are known as free blocks.
The first two bytes of each free block contain the offset of the next free block in the free block list formatted as a 2-byte big-endian integer, relative to the start of the database page. If there is no next free block, then the first two bytes are set to 0x00.
The second two bytes (byte offsets 2 and 3) of each free block contain the total size of the free block, formatted as a 2-byte big-endian integer.
On all B-Tree pages, the offset of the first free block in the free block list, relative to the start of the database page, is stored as a 2-byte big-endian integer starting at byte offset 1 of the database page. If there is no first free block (because the free block list is empty), then the two bytes at offsets 1 and 2 of the database page are set to 0x00. On page 1, this field is stored at byte offset 101 of the page.
Within the cell-content area, all blocks of contiguous free-space (space not used by B-Tree cells) less than or equal to 3 bytes in size are known as fragments. The total size of all fragments on a B-Tree page is stored as a 1-byte unsigned integer at byte offset 7 of the database page. On page 1, this field is stored at byte offset 107.
2.3.3.4 Index B-Tree Cell Format
For index B-Tree internal tree node pages, each B-Tree cell begins with a child page-number, stored as a 4-byte big-endian unsigned integer. This field is omitted for leaf pages, which have no children.
Following the child page number is the total number of bytes consumed by the cell's record, stored as a variable length integer (see section 2.3.1).
If the record is small enough, it is stored verbatim in the cell. A record is deemed to be small enough to be completely stored in the cell if it consists of less than or equal to:
max-local := (usable-size - 12) * max-embedded-fraction / 255 - 23
bytes. In the formula above, usable-size is the page-size in bytes less the number of unused bytes left at the end of every page (as read from byte offset 20 of the database header), and max-embedded-fraction is the value read from byte offset 21 of the database header.
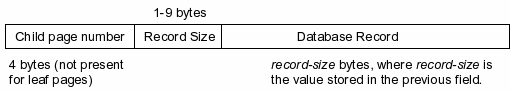
Figure 5 - Small Record Index B-Tree Cell
If the cell record is larger than the maximum size identified by the formula above, then only the first part of the record is stored within the cell. The remainder is stored in an overflow-chain (see section 2.3.5 for details). Following the part of the record stored within the cell is the page number of the first page in the overflow chain, stored as a 4 byte big-endian unsigned integer. The size of the part of the record stored within the B-Tree cell (local-size in figure 6) is calculated according to the following algorithm:
min-local := (usable-size - 12) * min-embedded-fraction / 255 - 23
max-local := (usable-size - 12) * max-embedded-fraction / 255 - 23
local-size := min-local + (record-size - min-local) % (usable-size - 4)
if( local-size > max-local )
local-size := min-local
In the formula above, usable-size is the page-size in bytes less the number of unused bytes left at the end of every page (as read from byte offset 20 of the database header), and max-embedded-fraction and min-embedded-fraction are the values read from byte offsets 21 and 22 of the database header, respectively.

Figure 6 - Large Record Index B-Tree Cell
Each B-Tree cell belonging to an internal node page of an index B-Tree consists of a 4-byte big-endian unsigned integer, the child page number, followed by a variable length integer field, followed by a database record. The variable length integer field contains the length of the database record in bytes.
Each B-Tree cell belonging to an leaf page of an index B-Tree consists of a variable length integer field, followed by a database record. The variable length integer field contains the length of the database record in bytes.
If the database record stored in an index B-Tree page is
sufficiently small, then the entire cell is stored within the
index B-Tree page. Sufficiently small is defined as equal to or
less than max-local, where:
max-local := (usable-size - 12) * 64 / 255 - 23
If the database record stored as part of an index B-Tree cell is too large to be stored entirely within the B-Tree page (as defined by H30520), then only a prefix of the database record is stored within the B-Tree page and the remainder stored in an overflow chain. In this case, the database record prefix is immediately followed by the page number of the first page of the overflow chain, formatted as a 4-byte big-endian unsigned integer.
When a database record belonging to a table B-Tree cell is
stored partially within an overflow page chain, the size
of the prefix stored within the index B-Tree page is N bytes,
where N is calculated using the following algorithm:
min-local := (usable-size - 12) * 32 / 255 - 23
max-local := (usable-size - 12) * 64 / 255 - 23
N := min-local + ((record-size - min-local) % (usable-size - 4))
if( N > max-local ) N := min-local
Requirements H31010 and H30990 are similar to the algorithms presented in the text above. However instead of min-embedded-fraction and max-embedded-fraction the requirements use the constant values 32 and 64, as well-formed database files are required by H30080 and H30070 to store these values in the relevant database database header fields.
2.3.4 Table B-Trees
As noted in section 2.1, table B-Trees store a set of unique 64-bit signed integer keys. Associated with each key is a database record. As with index B-Trees, the database file pages that make up a table B-Tree are organized into a tree structure with a single "root" page at the head of the tree.
Unlike index B-Tree structures, where entries are stored on both internal and leaf nodes, all entries in a table B-Tree are stored in the leaf nodes. Within each leaf node, keys are stored in sorted order.
Each internal tree node contains an ordered list of N references to child pages, where N is some number greater than one. In a similar manner to the way in which an index B-Tree page would contain N-1 records, each internal table B-Tree node page also contains a list of N-1 64-bit signed integer values in sorted order. The keys are distributed throughout the tree such that for all internal tree nodes, integer I(n) is equal to the largest key value stored in the sub-tree headed by child page C(n) for values of n between 0 and N-2, inclusive. Additionally, all keys stored in the sub-tree headed by child page C(n+1) have values larger than that of I(n), for values of n in the same range.
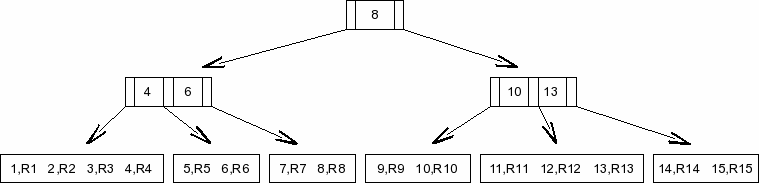
Figure 7 - Table B-Tree Tree Structure
Figure 7 depicts a table B-Tree containing a contiguous set of 14 integer keys starting with 1. Each key n has an associated database record Rn. All the keys and their associated records are stored in the leaf pages. The internal node pages contain no database data, their only purpose is to provide a way to navigate the tree structure.
The pages in a table B-Tree structures are arranged into a tree structure such that all leaf pages are at the same depth.
Each leaf page in a table B-Tree structure contains one or more B-Tree cells, where each cell contains a 64-bit signed integer key value and a database record.
Each internal node page in a table B-Tree structure contains one or more B-Tree cells, where each cell contains a 64-bit signed integer key value, K, and a child page number, C. All integer key values in all B-Tree cells within the sub-tree headed by page C are less than or equal to K. Additionally, unless K is the smallest integer key value stored on the internal node page, all integer keys within the sub-tree headed by C are greater than K-1, where K-1 is the largest integer key on the internal node page that is smaller than K.
As well as child page numbers associated with B-Tree cells, each internal node page in a table B-Tree contains the page number of an extra child page, the right-child page. All key values in all B-Tree cells within the sub-tree headed by the right-child page are greater than all key values stored within B-Tree cells on the internal node page.
The special case for root page 1. Root page 1 may contain zero cells, just a right-child pointer to the only other b-tree page in the tree.
The precise way in which table B-Tree pages and cells are formatted is described in subsequent sections.
2.3.4.1 Table B-Tree Content
The database file contains one table B-Tree for each database table in the logical database. Although some data may be duplicated in index B-Tree structures, the table B-Tree is the primary location of table data.
The table B-Tree contains exactly one entry for each row in the database table. The integer key value used for the B-Tree entry is the value of the "rowid" field of the corresponding logical row in the database table. The database row fields are stored in the record associated with the table B-Tree entry, in the same order as they appear in the logical database table. The first field in the record (see section 2.3.2) contains the value of the leftmost field in the database row, and so on.
If a database table column is declared as an INTEGER PRIMARY KEY, then it is an alias for the rowid field, which is stored as the table B-Tree key value. Instead of duplicating the integer value in the associated record, the record field associated with the INTEGER PRIMARY KEY column is always set to an SQL NULL.
Finally, if the schema layer file-format is greater than or equal to 2, some of the records stored in table B-Trees may contain less fields than the associated logical database table does columns. If the schema layer file-format is exactly 2, then the logical database table column values associated with the "missing" fields are SQL NULL. If the schema layer file-format is greater than 2, then the values associated with the "missing" fields are determined by the default value of the associated database table columns. Reference to CREATE TABLE syntax. How are default values determined?
In a well-formed database, each table B-Tree contains a single entry for each row in the corresponding logical database table.
The key value (a 64-bit signed integer) for each B-Tree entry is the same as the value of the rowid field of the corresponding logical database row.
The SQL values serialized to make up each database record stored as ancillary data in a table B-Tree shall be the equal to the values taken by the N leftmost columns of the corresponding logical database row, where N is the number of values in the database record.
If a logical database table column is declared as an "INTEGER PRIMARY KEY", then instead of its integer value, an SQL NULL shall be stored in its place in any database records used as ancillary data in a table B-Tree.
The following database properties discuss table B-Tree records with implicit (default) values.
If the database schema layer file-format (the value stored as a 4-byte integer at byte offset 44 of the file header) is 1, then all database records stored as ancillary data in a table B-Tree structure have the same number of fields as there are columns in the corresponding logical database table.
If the database schema layer file-format value is two or greater and the rightmost M columns of a row contain SQL NULL values, then the corresponding record stored as ancillary data in the table B-Tree has between N-M and N fields, where N is the number of columns in the logical database table.
If the database schema layer file-format value is three or greater and the rightmost M columns of a row contain their default values according to the logical table declaration, then the corresponding record stored as ancillary data in the table B-Tree may have as few as N-M fields, where N is the number of columns in the logical database table.
2.3.4.2 Table B-Tree Page Format
Table B-Tree structures use the same page format as index B-Tree structures, described in section 2.3.3.3, with the following differences:
- The first byte of the page-header, the "flags" field, is set to 0x05 for internal tree node pages, and 0x0D for leaf pages.
- The content and format of the B-Tree cells is different. See section 2.3.4.3 for details.
- The format of page 1 is the same as any other table B-Tree, except that 100 bytes less than usual is available for content. The first 100 bytes of page 1 is consumed by the database header.
In a well-formed database file, the first byte of each page used as an internal node of a table B-Tree structure is set to 0x05.
In a well-formed database file, the first byte of each page used as a leaf node of a table B-Tree structure is set to 0x0D.
Most of the requirements specified in section 2.3.3.3 also apply to table B-Tree pages. The wording of the requirements make it clear when this is the case, either by referring to generic "B-Tree pages" or by explicitly stating that the statement applies to both "table and index B-Tree pages".
2.3.4.3 Table B-Tree Cell Format
Cells stored on internal table B-Tree nodes consist of exactly two fields. The associated child page number, stored as a 4-byte big-endian unsigned integer, followed by the 64-bit signed integer value, stored as a variable length integer (section 2.3.1). This is depicted graphically in figure 8.
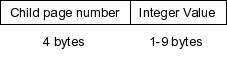
Figure 8 - Table B-Tree Internal Node Cell
Cells of table B-Tree leaf pages are required to store a 64-bit signed integer key and its associated database record. The first two fields of all table B-Tree leaf page cells are the size of the database record, stored as a variable length integer (see section 2.3.1), followed by the key value, also stored as a variable length integer. For sufficiently small records, the entire record is stored in the B-Tree cell following the record-size field. In this case, sufficiently small is defined as less than or equal to:
max-local := usable-size - 35
bytes. Where usable-size is defined as the page-size in bytes less the number of unused bytes left at the end of every page (as read from byte offset 20 of the database header). This scenario, where the entire record is stored within the B-Tree cell, is depicted in figure 9.

Figure 9 - Table B-Tree Small Record Leaf Node Cell
If the record is too large to be stored entirely within the B-Tree cell, then the first part of it is stored within the cell and the remainder in an overflow chain (see section 2.3.5). The size of the part of the record stored within the B-Tree cell (local-size in figure 10) is calculated according to the following algorithm (a similar procedure to that used to calculate the portion of an index B-Tree key to store within the cell when an overflow chain is required):
min-local := (usable-size - 12) * min-embedded-fraction / 255 - 23
max-local := usable-size - 35
local-size := min-local + (record-size - min-local) % (usable-size - 4)
if( local-size > max-local )
local-size := min-local
In this case, min-embedded-fraction is the value read from byte offset 22 of the database header. The layout of the cell in this case, when an overflow-chain is required, is shown in figure 10.

Figure 10 - Table B-Tree Large Record Leaf Node Cell
If the leaf page is page 1, then the value of usable-size is as it would be for any other B-Tree page, even though the actual usable size is 100 bytes less than this for page 1 (because the first 100 bytes of the page is consumed by the database file header).
The following requirements describe the format of table B-Tree cells, and the distribution thereof between B-Tree and overflow pages.
B-Tree cells belonging to table B-Tree internal node pages consist of exactly two fields, a 4-byte big-endian unsigned integer immediately followed by a variable length integer. These fields contain the child page number and key value respectively (see H31030).
B-Tree cells belonging to table B-Tree leaf node pages consist of three fields, two variable length integer values followed by a database record. The size of the database record in bytes is stored in the first of the two variable length integer fields. The second of the two variable length integer fields contains the 64-bit signed integer key (see H31030).
If the size of the record stored in a table B-Tree leaf page cell is less than or equal to (usable page size-35) bytes, then the entire cell is stored on the B-Tree leaf page. In a well-formed database, usable page size is the same as the database page size.
If a table B-Tree cell is too large to be stored entirely on a leaf page (as defined by H31170), then a prefix of the cell is stored on the leaf page, and the remainder stored in an overflow page chain. In this case the cell prefix stored on the B-Tree leaf page is immediately followed by a 4-byte big-endian unsigned integer containing the page number of the first overflow page in the chain.
When a table B-Tree cell is stored partially in an
overflow page chain, the prefix stored on the B-Tree
leaf page consists of the two variable length integer fields,
followed by the first N bytes of the database record, where
N is determined by the following algorithm:
min-local := (usable-size - 12) * 32 / 255 - 23
max-local := (usable-size - 35)
N := min-local + (record-size - min-local) % (usable-size - 4)
if( N > max-local ) N := min-local
Requirement H31190 is very similar to the algorithm presented in the text above. Instead of min-embedded-fraction, it uses the constant value 32, as well-formed database files are required by H30090 to store this value in the relevant database file header field.
2.3.5 Overflow Page Chains
Sometimes, a database record stored in either an index or table B-Trees is too large to fit entirely within a B-Tree cell. In this case part of the record is stored within the B-Tree cell and the remainder stored on one or more overflow pages. The overflow pages are chained together using a singly linked list. The first 4 bytes of each overflow page is a big-endian unsigned integer value containing the page number of the next page in the list. The remaining usable database page space is available for record data.

Figure 11 - Overflow Page Format
The scenarios in which overflow pages are required and the number of bytes stored within the B-Tree cell in each are described for index and table B-Trees in sections 2.3.3.4 and 2.3.4.3 respectively. In each case the B-Tree cell also stores the page number of the first page in a linked list of overflow pages.
The amount of space available for record data on each overflow page is:
available-space := usable-size - 4
Where usable-size is defined as the page-size in bytes less the number of unused bytes left at the end of every page (as read from byte offset 20 of the database header).
Each overflow page except for the last one in the linked list contains available-space bytes of record data. The last page in the list contains the remaining data, starting at byte offset 4. The value of the "next page" field on the last page in an overflow chain is undefined.
A single overflow page may store up to available-space bytes of database record data, where available-space is equal to (usable-size - 4).
When a database record is too large to store within a B-Tree page (see H31170 and H31000), a prefix of the record is stored within the B-Tree page and the remainder stored across N overflow pages. In this case N is the minimum number of pages required to store the portion of the record not stored on the B-Tree page, given the maximum payload per overflow page defined by H31200.
The list of overflow pages used to store a single database record are linked together in a singly linked list known as an overflow chain. The first four bytes of each page except the last in an overflow chain are used to store the page number of the next page in the linked list, formatted as an unsigned big-endian integer. The first four bytes of the last page in an overflow chain are set to 0x00.
Each overflow page except the last in an overflow chain contains N bytes of record data starting at byte offset 4 of the page, where N is the maximum payload per overflow page, as defined by H31200. The final page in an overflow chain contains the remaining data, also starting at byte offset 4.
2.4 The Free Page List
Sometimes, after deleting data from the database, SQLite removes pages from B-Tree structures. If these pages are not immediately required for some other purpose, they are placed on the free page list. The free page list contains those pages that are not currently being used to store any valid data.
Each page in the free-list is classified as a free-list trunk page or a free-list leaf page. All trunk pages are linked together into a singly linked list (in the same way as pages in an overflow chain are - see section 2.3.5). The first four bytes of each trunk page contain the page number of the next trunk page in the list, formatted as an unsigned big-endian integer. If the trunk page is the last page in the linked list, the first four bytes are set to zero.
Bytes 4 to 7 of each free-list trunk page contain the number of references to free-list leaf pages (page numbers) stored on the free-list trunk page. Each leaf page on the free-list is referenced by exactly one trunk page.
The remaining space on a free-list trunk page is used to store the page numbers of free-list leaf pages as 4 byte big-endian integers. Each free-list trunk page contains up to:
max-leaf-pointers := (usable-size - 8) / 4
pointers, where usable-size is defined as the page-size in bytes less the number of unused bytes left at the end of every page (as read from byte offset 20 of the database header).

Figure 12 - Free List Trunk Page Format
All trunk pages in the free-list except for the first contain the maximum possible number of references to leaf pages. Is this actually true in an auto-vacuum capable database? Later: No, not even nearly true. It is a false statement. The page number of the first page in the linked list of free-list trunk pages is stored as a 4-byte big-endian unsigned integer at offset 32 of the database header (section 2.2.1).
All free pages in a well-formed database file are part of the database free page list.
Each free page is either a free list trunk page or a free list leaf page.
All free list trunk pages are linked together into a singly linked list. The first 4 bytes of each page in the linked list contains the page number of the next page in the list, formatted as an unsigned big-endian integer. The first 4 bytes of the last page in the linked list are set to 0x00.
The second 4 bytes of each free list trunk page contains the number of free list leaf page numbers stored on the free list trunk page, formatted as an unsigned big-endian integer.
Beginning at byte offset 8 of each free list trunk page are N page numbers, each formatted as a 4-byte unsigned big-endian integers, where N is the value described in requirement H31270.
All page numbers stored on all free list trunk pages refer to database pages that are free list leaves.
The page number of each free list leaf page in a well-formed database file appears exactly once within the set of pages numbers stored on free list trunk pages.
The following statements govern the two 4-byte big-endian integers associated with the free page list structure in the database header.
The total number of pages in the free list, including all free list trunk and free list leaf pages, is stored as a 4-byte unsigned big-endian integer at offset 36 of the database file header.
The page number of the first page in the linked list of free list trunk pages is stored as a 4-byte big-endian unsigned integer at offset 32 of the database file header. If there are no free list trunk pages in the database file, then the value stored at offset 32 of the database file header is 0.
2.5 Pointer Map Pages
Pointer map pages are only present in auto-vacuum capable databases. A database is an auto-vacuum capable database if the value stored at byte offset 52 of the file-header is non-zero.
If they are present, the pointer-map pages together form a lookup table that can be used to determine the type and "parent page" of any page in the database, given its page number. The lookup table classifies pages into the following categories:
| Page Type | Byte Value | Description |
|---|---|---|
| B-Tree Root Page | 0x01 | The page is the root page of a table or index B-Tree structure. There is no parent page number in this case, the value stored in the pointer map lookup table is always zero. |
| Free Page | 0x02 | The page is part of the free page list (section 2.4). There is no parent page in this case, zero is stored in the lookup table instead of a parent page number. |
| Overflow type 1 | 0x03 | The page is the first page in an overflow chain. The parent page is the B-Tree page containing the B-Tree cell to which the overflow chain belongs. |
| Overflow type 2 | 0x04 | The page is part of an overflow chain, but is not the first page in that chain. The parent page is the previous page in the overflow chain linked-list. |
| B-Tree Page | 0x05 | The page is part of a table or index B-Tree structure, and is not an overflow page or root page. The parent page is the page containing the parent tree node in the B-Tree structure. |
Pointer map pages themselves do not appear in the pointer-map lookup table. Page 1 does not appear in the pointer-map lookup table either.

Figure 13 - Pointer Map Entry Format
Each pointer-map lookup table entry consumes 5 bytes of space. The first byte of each entry indicates the page type, according to the key described in the table above. The following 4 bytes store the parent page number as a big-endian unsigned integer. This format is depicted in figure 13. Each pointer-map page may therefore contain:
num-entries := usable-size / 5
entries, where usable-size is defined as the page-size in bytes less the number of unused bytes left at the end of every page (as read from byte offset 20 of the database header).
Assuming the database is auto-vacuum capable, page 2 is always a pointer map page. It contains the pointer map lookup table entries for pages 3 through (2 + num-entries), inclusive. The first 5 bytes of page 2 contain the pointer map lookup table entry for page 3. Bytes 5 through 9, inclusive, contain the pointer map lookup table entry for page 4, and so on.
The next pointer map page in the database is page number (3 + num-entries), which contains the pointer map entries for pages (4 + num-entries) through (3 + 2 * num-entries) inclusive. In general, for any value of n greater than zero, the following page is a pointer-map page that contains lookup table entries for the num-entries pages that follow it in the database file:
pointer-map-page-number := 2 + n * num-entries
Non auto-vacuum databases do not contain pointer map pages.
In an auto-vacuum database file, every (num-entries + 1)th
page beginning with page 2 is designated a pointer-map page, where
num-entries is calculated as:
num-entries := database-usable-page-size / 5
In an auto-vacuum database file, each pointer-map page contains a pointer map entry for each of the num-entries (defined by H31340) pages that follow it, if they exist.
Each pointer-map page entry consists of a 1-byte page type and a 4-byte page parent number, 5 bytes in total.
Pointer-map entries are packed into the pointer-map page in order, starting at offset 0. The entry associated with the database page that immediately follows the pointer-map page is located at offset 0. The entry for the following page at offset 5 etc.
The following requirements govern the content of pointer-map entries.
For each page except page 1 in an auto-vacuum database file that is the root page of a B-Tree structure, the page type of the corresponding pointer-map entry is set to the value 0x01 and the parent page number is zero.
For each page that is a part of an auto-vacuum database file free-list, the page type of the corresponding pointer-map entry is set to the value 0x02 and the parent page number is zero.
For each page in a well-formed auto-vacuum database that is the first page in an overflow chain, the page type of the corresponding pointer-map entry is set to 0x03 and the parent page number field is set to the page number of the B-Tree page that contains the start of the B-Tree cell stored in the overflow-chain.
For each page that is the second or a subsequent page in an overflow chain, the page type of the corresponding pointer-map entry is set to 0x04 and the parent page number field is set to the page number of the preceding page in the overflow chain.
For each page that is not a root page but is a part of a B-Tree tree structure (not part of an overflow chain), the page type of the corresponding pointer-map entry is set to the value 0x05 and the parent page number field is set to the page number of the parent node in the B-Tree structure.
3 Database File-System Representation
The previous section, section 2 describes the format of an SQLite database image. A database image is the serialized form of a logical SQLite database. Normally, a database image is stored within the file-system in a single file, a database file. In this case no other data is stored within the database file. The first byte of the database file is the first byte of the database image, and the last byte of the database file is the last byte of the database image. For this reason, SQLite is often described as a "single-file database system". However, an SQLite database image is not always stored in a single file within the file-system. It is also possible for it to be distributed between the database file and a journal file. A third file, a master-journal file may also be part of the file-system representation. Although a master-journal file never contains any part of the database image, it can contain meta-data that helps determine which parts of the database image are stored within the database file, and which parts are stored within the journal file.
In other words, the file-system representation of an SQLite database consists of the following:
-
A main database file. The database file is always present. It may be zero bytes in size, but it is always present.
-
Optionally, a journal file. If present, the journal file is stored in the same file-system directory as the database file. The name of the journal file is the same as that of the database file with the string "-journal" appended to it.
-
Optionally, a master-journal file may also be part of the file-system representation of a database image. A master-journal file may only be part of the representation if the journal file is present. A master-journal file may be located anywhere within the file-system and may take any name. If present, the master-journal is identified by the master-journal pointer stored in the journal file (see section 3.1.1.3 for details).
Usually, a database image is stored entirely within the database file. Other configurations, where the database image data is distributed between the database file and its journal file, are used as interim states when modifying the contents of the database image to commit a database transaction. In practice, a database reader only encounters such a configuration if a previous attempt to modify the database image on disk was interrupted by an application, OS or power failure. The most practical approach (and that taken by SQLite) is to extract the subset of the database image currently stored within the journal file and write it into the database file, thus restoring the system to a state where the database file contains the entire database image. Other SQLite documentation, and the comments in the SQLite source code, identify this process as hot journal rollback. Instead of focusing on the hot journal rollback process, this document describes how journal and master-journal files must be interpreted in order to extract the current database image from the file-system representation in the general case.
Sub-section 3.1 describes the formats used by journal and master-journal files.
Sub-section 3.2 contains a precise description of the various ways a database image may be distributed between the database file and journal file, and the rules that must be followed to extract it. In other words, a description of how SQLite or compatible software reads the database image from the file-system.
3.1 Journal File Formats
The following sub-sections describe the formats used by SQLite journal files (section 3.1.1) and master journal files (section 3.1.2).
3.1.1 Journal File Details
This section describes the format used by an SQLite journal file.
A journal file consists of one or more journal sections, optionally followed by a master journal pointer field. The first journal section starts at the beginning of the journal file. There is no limit to the number of journal sections that may be present in a single journal file.
Each journal section consists of a journal header immediately followed by zero or more journal records. The format of journal header and journal records are described in sections 3.1.1.1 and 3.1.1.2 respectively. One of the numeric fields stored in a journal header is the sector size field. Each journal section in a journal file must be an integer multiple of the sector size stored in the first journal header of the journal file (the value of the sector size field in the second and subsequent journal headers is not used). If the sum of the sizes of the journal header and journal records in a journal section is not an integer multiple of the sector size, then up to (sector-size - 1) bytes of unused space (padding) follow the end of the last journal record to make up the required length.
Figure 14 illustrates a journal file that contains N journal sections and a master journal pointer. The first journal section in the file is depicted as containing M journal records.
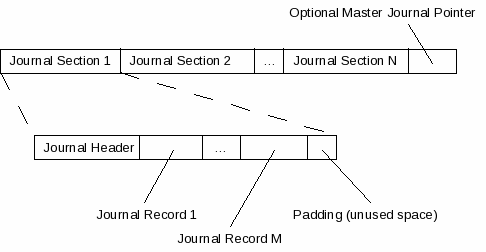
Figure 14 - Journal File Format
The following requirements define a well-formed journal section. This concept is used in section 3.2.
A buffer shall be considered to contain a well-formed journal section if it is not excluded from this category by requirements H32220, H32230 or H32240.
A buffer shall only be considered to contain a well-formed journal section if the first 28 bytes of it contain a well-formed journal header.
A buffer shall only be considered to contain a well-formed journal section if, beginning at byte offset sector-size, it contains a sequence of record-count well-formed journal records. In this case sector-size and record-count are the integer values stored in the sector size and record count fields of the journal section's journal header.
A buffer shall only be considered to contain a well-formed journal section if it is an integer multiple of sector-size bytes in size, where sector-size is the value stored in the sector size field of the journal section's journal header.
Note that a journal section that is not strictly speaking a well-formed journal section often contains important data. For example, many journal files created by SQLite that consist of a single journal section and no master journal pointer contain a journal section that is not well-formed according to requirement H32240. See section 3.2 for details on when well-formedness is an important property of journal sections and when it is not.
3.1.1.1 Journal Header Format
A journal header is sector-size bytes in size, where sector-size is the value stored as a 32-bit big-endian unsigned integer at byte offset 20 of the first journal header that occurs in the journal file. The sector-size must be an integer power of two greater than or equal to 512. The sector-size is chosen by the process that creates the journal file based on the considerations described in section writing_to_files. Only the first 28 bytes of the journal header are used, the remainder may contain garbage data. The first 28 bytes of each journal header consists of an eight byte block set to a well-known value, followed by five big-endian 32-bit unsigned integer fields.
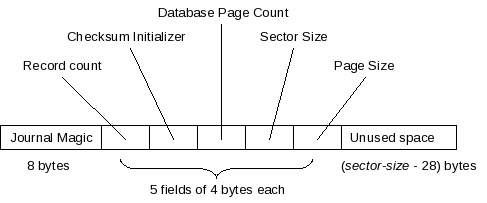
Figure 15 - Journal Header Format
Figure 15 graphically depicts the layout of a journal header. The individual fields are described in the following table. The offsets in the 'byte offset' column of the table are relative to the start of the journal header.
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 8 | The journal magic field always contains a
well-known 8-byte string value used to identify SQLite
journal files. The well-known sequence of byte values
is:
0xd9 0xd5 0x05 0xf9 0x20 0xa1 0x63 0xd7 |
| 8 | 4 | This field, the record count, is set to the number of journal records that follow this journal header in the journal file. |
| 12 | 4 | The checksum initializer field is set to a pseudo-random value. It is used as part of the algorithm to calculate the checksum for all journal records that follow this journal header. |
| 16 | 4 | This field, the database page count, is set to the number of pages that the database file contained before any modifications associated with write transaction are applied. |
| 20 | 4 | This field, the sector size, is set to the sector size of the device on which the journal file was created, in bytes. This value is required when reading the journal file to determine the size of each journal header. |
| 24 | 4 | The page size field contains the database page size used by the corresponding database file when the journal file was created, in bytes. |
Because a journal header always occurs at the start of a journal section, and because the size of each journal section is always a multiple of sector-size bytes, journal headers are always positioned in the file such that they start at a sector-size aligned offset.
The following requirements define a "well-formed journal header". This concept is used in the following sections. A well-formed journal header is defined as a blob of 28 bytes for which the journal magic field is set correctly and for which both the page size and sector size fields are set to power of two values greater than 512. Because there are no restrictions on the values that may be stored in the record count, checksum initializer or database page count fields, they do not enter into the definition of a well-formed journal header.
A buffer of 28 bytes shall be considered a well-formed journal header if it is not excluded by requirements H32180, H32190 or H32200.
A buffer of 28 bytes shall only be considered a well-formed journal header if the first eight bytes of the buffer contain the values 0xd9, 0xd5, 0x05, 0xf9, 0x20, 0xa1, 0x63, and 0xd7, respectively.
A buffer of 28 bytes shall only be considered a well-formed journal header if the value stored in the sector size field (the 4-byte big-endian unsigned integer at offset 20 of the buffer) contains a value that is an integer power of two greater than 512.
A buffer of 28 bytes shall only be considered a well-formed journal header if the value stored in the page size field (the 4-byte big-endian unsigned integer at offset 24 of the buffer) contains a value that is an integer power of two greater than 512.
3.1.1.2 Journal Record Format
Each journal record contains the data for a single database page, a page number identifying the page, and a checksum value used to help detect journal file corruption.

Figure 16 - Journal Record Format
A journal record, depicted graphically by figure 16, contains three fields, as described in the following table. Byte offsets are relative to the start of the journal record.
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 4 | The page number of the database page associated with this journal record, stored as a 4 byte big-endian unsigned integer. |
| 4 | page-size | This field contains the original data for the page, exactly as it appeared in the database file before the write transaction began. |
| 4 + page-size | 4 | This field contains a checksum value, calculated based on the contents of the journaled database page data (the previous field) and the values stored in the checksum initializer field of the preceding journal header. |
The checksum value stored in each journal record is calculated based on the contents of the page data field of the record and the value stored in the checksum initializer field of the journal header that occurs immediately before the journal record. The checksum initializer field is interpreted as a 32-bit unsigned integer. To this value is added the value stored in every 200th byte of the page data field, interpreted as an 8-bit unsigned integer, beginning with the byte at offset (page-size % 200). The sum is accumulated in a 32-bit unsigned integer. Overflow is handled by wrapping around to zero.
Sum of values:
0xFFFFFFE1 +
0x00000023 +
0x00000032 +
0x0000009E +
0x00000062 +
0x0000001F
-----------
0x100000155
Truncated to 32-bits:
0x00000155
For example, if the page-size is 1024 bytes, then the offsets within the page of the bytes added to the checksum initializer value are 24, 224, 424, 624 and 824 (the first byte of the page is offset 0, the last byte is offset 1023). If the values of the bytes at these offsets are 0x23, 0x32, 0x9E, 0x62 and 0x1F, and the value of the checksum initializer field is 0xFFFFFFE1, then the value stored in the checksum field of the journal record is 0x00000155.
The set of journal records that follow a journal header in a journal file are packed tightly together. There are no alignment requirements for journal records.
A buffer of (8 + page size) bytes shall be considered a well-formed journal record if it is not excluded by requirements H32110 or H32120.
A journal record shall only be considered to be well-formed if the page number field contains a value other than zero and the locking-page number, calculated using the page size found in the first journal header of the journal file that contains the journal record.
A journal record shall only be considered to be well-formed if the checksum field contains a value equal to the sum of the value stored in the checksum-initializer field of the journal header that precedes the record and the value stored in every 200th byte of the page data field, interpreted as an 8-bit unsigned integer), starting with byte offset (page-size % 200) and ending with the byte at byte offset (page-size - 200).
3.1.1.3 Master Journal Pointer
If present, a master journal pointer occurs at the end of a journal file. There may or may not be unused space between the end of the final journal section and the start of the master journal pointer.
A master journal pointer contains the full path of a master journal-file along with a check-sum and some well-known values that allow the master journal pointer to be unambiguously distinguished from a journal record or journal header.
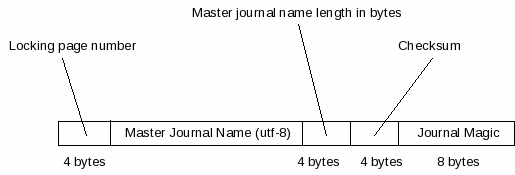
Figure 17 - Master Journal Pointer Format
A master journal pointer, depicted graphically by figure 17, contains five fields, as described in the following table. Byte offsets are relative to the start of the master journal pointer.
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 4 | This field, the locking page number, is always set to the page number of the database locking page stored as a 4-byte big-endian integer. The locking page is the page that begins at byte offset 230 of the database file. Even if the database file is large enough to contain the locking page, the locking page is never used to store any data and so the first four bytes of of a valid journal record will never contain this value. |
| 4 | name-length | The master journal name field contains the name of the master journal file, encoded as a utf-8 string. There is no nul-terminator appended to the string. |
| 4 + name-length | 4 | The name-length field contains the length of the previous field in bytes, formatted as a 4-byte big-endian unsigned integer. |
| 8 + name-length | 4 | The checksum field contains a checksum value stored as a 4-byte big-endian signed integer. The checksum value is calculated as the sum of the bytes that make up the master journal name field, interpreting each byte as an 8-bit signed integer. |
| 12 + name-length | 8 |
Finally, the journal magic field always contains a
well-known 8-byte string value; the same value stored in the
first 8 bytes of a journal header. The well-known
sequence of bytes is:
0xd9 0xd5 0x05 0xf9 0x20 0xa1 0x63 0xd7 |
A buffer shall only be considered to be a well-formed master journal pointer if the final eight bytes of the buffer contain the values 0xd9, 0xd5, 0x05, 0xf9, 0x20, 0xa1, 0x63, and 0xd7, respectively.
A buffer shall only be considered to be a well-formed master journal pointer if the size of the buffer in bytes is equal to the value stored as a 4-byte big-endian unsigned integer starting 16 bytes before the end of the buffer.
A buffer shall only be considered to be a well-formed master journal pointer if the first four bytes of the buffer, interpreted as a big-endian unsigned integer, contain the page number of the locking page (the value (1 + 230 / page-size), where page-size is the value stored in the page-size field of the first journal header of the journal file).
A buffer shall only be considered to be a well-formed master journal pointer if the value stored as a 4-byte big-endian integer starting 12 bytes before the end of the buffer is equal to the sum of all bytes, each interpreted as an 8-bit unsigned integer, starting at offset 4 of the buffer and continuing until offset (buffer-size - 16) (the 17th last byte of the buffer).
3.1.2 Master-Journal File Details
A master-journal file contains the full paths to two or more journal files, each encoded using UTF-8 encoding and terminated by a single nul character (byte value 0x00). There is no padding between the journal paths, each UTF-8 encoded path begins immediately after the nul character that terminates the previous one.
Note that the contents of a master-journal is not really all that important, and is not required at all to read the database image. Used for cleanup only.
3.2 Reading an SQLite Database
As described in section 2.2.2 of this document, an SQLite database image is a set of contiguously numbered fixed size pages. The numbering starts at 1, not 0. Page 1 contains the database header and the root page of the schema table, and all other pages within the database image are somehow referenced by number, either directly or indirectly, from page 1, either directly or indirectly. In order to be able to read the database image from within the file-system, a database reader needs to be able to ascertain:
- The page-size used by the database image,
- The number of pages in the database image, and
- The content of each database page.
Usually, the database image is simply the contents of the database file. In this case, reading the database image is straightforward. The page-size used by the database image can be read from the 2-byte big-endian integer field stored at byte offset 16 of the database file (see section 2.2.1). The number of pages in the database image can be determined by querying the size of the database file in bytes and then dividing by the page-size. Reading the contents of a database page is a simple matter of reading a block of page-size bytes from an offset calculated from the page-number of the required page:
offset := (page-number - 1) * page-size
However, if there is a valid journal file corresponding to the database file present within the file-system then the situation is more complicated. The file-system is considered to contain a valid journal file if each of the following conditions are met:
- A journal file is present in the file system, and
- the journal file either does not end with a well-formed master-journal pointer (see section 3.1.1.3) or the master-journal file referred to by the master-journal pointer is present in the file-system, and
- the first 28 bytes of the journal file contain a well-formed journal header (see section 3.1.1.1).
If the file system contains a valid journal file, then the page-size used by and the number of pages in the database image are stored in the first journal header of the journal file. Specifically, the page-size is stored as a 4-byte big-endian unsigned integer at byte offset 24 of the journal file, and the number of pages in the database image is stored as a 4-byte big-endian unsigned integer at byte offset of 16 of the same file.
The current data for each page of the database image may be stored within the database file at a file offset based on its page number as it normally is, or the current version of the data may be stored somewhere within the journal file. For each page within the database image, if the journal file contains a valid journal record for the corresponding page-number, then the current content of the database image page is the blob of data stored in the page data field of the journal record. If the journal file does not contain a valid journal record for a page, then the current content of the database image page is the blob of data currently stored in the corresponding region of the database file.
Not all journal records within a journal file are valid. A journal record is said to be valid if:
- The journal file that contains the journal record is a valid journal file, and
- all journal sections that occur before the journal section containing the journal record are well-formed, and
- the journal section that contains the journal record begins with a well-formed journal header, and
- the journal record itself and all journal records that occur before it in the same journal section are well-formed.
Note that it is not necessary for a journal record to be part of a well-formed journal section to be considered valid.
Figure 18 illustrates two distinct ways to store a database image within the file system. In this example, the database image consists of 4 pages of page-size bytes each. The content of each of the 4 pages is designated A, B, C and D, respectively. Representation 1 uses only the database file. In this case the entire database image is stored in the database file.
In representation 2 of figure 18, the current database images is stored using both the journal file and the database file. The size and page-size of the database image are both stored in the first (in this case only) journal header in the journal file. Following the journal header are two valid journal records. These contain the data for pages 3 and 4 of the database image. Because there are no valid journal records for pages 1 and 2 of the database image, the content for each of these is stored in the database file. Even though the contents of the file-system is quite different in representation 2 as in representation 1, the stored database image is the same in each case: 4 pages of page-size bytes each, content A, B, C and D respectively.
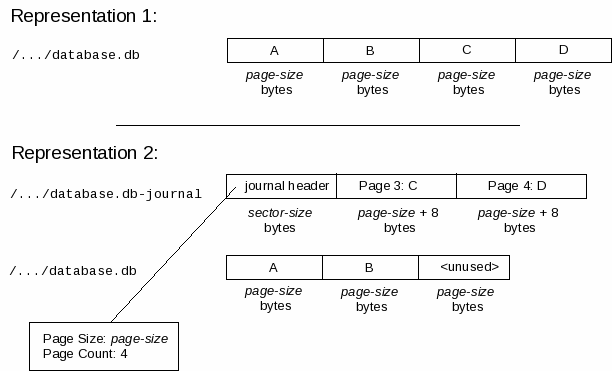
Figure 18 - Two ways to store the same database image
The requirements that follow talk about "well-formed" journal sections, records and master-journal-pointers. There should be some kind of reference back to the definitions of these things. Either in the requirements themselves (refer to other requirements by number) or in the surrounding text (point to document sections). Or, better, both.
These requirements describe the way a database reader must determine whether or not there is a valid journal file within the file-system.
If a journal file contains a well-formed master-journal pointer and the named master-journal file does not exist then the journal file shall be considered invalid.
If the first 28 bytes of a journal file do not contain a well-formed journal header, then the journal file shall be considered invalid.
If the journal file exists within the file-system and neither H32000 , H32010 nor H33080 apply, then the journal file shall be considered valid.
If there is a valid journal file within the file-system, the following requirements govern how a reader should determine the set of valid journal records that it contains.
A journal record found within a valid journal file shall be considered a valid journal record if it is not excluded from this category by requirement H32260, H32270 or H32280.
A journal record shall only be considered a valid journal record if it and any other journal records that occur before it within the same journal section are well-formed.
A journal record shall only be considered a valid journal record if the journal section to which it belongs begins with a well-formed journal header.
A journal record shall only be considered a valid journal record if all journal sections that occur before the journal section containing the journal record are well-formed journal sections.
The following requirements dictate the way in which database page-size and the number of pages in the database image should be determined by the reader.
If there exists a valid journal file in the file-system, then the database page-size in bytes used to interpret the database image shall be the value stored as a 4-byte big-endian unsigned integer at byte offset 24 of the journal file.
If there exists a valid journal file in the file-system, then the number of pages in the database image shall be the value stored as a 4-byte big-endian unsigned integer at byte offset 24 of the journal file.
If there is no valid journal file in the file-system, then the database page-size in bytes used to interpret the database image shall be the value stored as a 2-byte big-endian unsigned integer at byte offset 16 of the database file.
If there is no valid journal file in the file-system, then the number of pages in the database image shall be calculated by dividing the size of the database file in bytes by the database page-size.
The following requirements dictate the way in which the data for each page of the database image can be located within the file-system by a database reader.
If there exists a valid journal file in the file-system, then the contents of each page of the database image for which there is a valid journal record in the journal file shall be read from the corresponding journal record.
The contents of all database image pages for which there is no valid journal record shall be read from the database file.
4 SQLite Interoperability Requirements
This section contains requirements that further constrains the behaviour of software that accesses (reads and/or writes) SQLite databases stored within the file-system. These requirements need only be implemented by systems that access databases while other clients may also be doing so. More specifically, they need only be implemented by software operating within a system where one or more of the database clients writes to the database. If the database file-system representation remains constant at all times, or if there is only ever a single database client for each database within the system, the requirements in this section can be ignored.
The requirements in this section fall into three categories:
-
Database Writer Requirements. Section 4.1 contains notes on and requirements that must be observed by software systems that update an existing SQLite database image within the file-system.
-
Locking Requirements. Section 4.2 contains a description of the file-system locks that must be obtained on the database file, and how locks placed by other database clients should be interpreted.
-
Header Cookie Requirements. An SQLite database image header (see section 2.2.1) contains two "cookie" values that must sometimes be incremented when the database image stored in the file-system is updated. Section 4.3 contains requirements identifying exactly when the cookie values must be incremented, and how they can be used by a database client to determine if cached data is valid or not.
4.1 Writing to an SQLite Database File
When writing to an SQLite database, the database representation on disk must be modified to reflect the new, modified, database image. Exactly how this is done in terms of raw IO operations depends on the characteristics of the file-system in which the database is stored and the degree to which the application is required to handle failures within the system. A failure may be an application crash, an operating system crash, a power failure or other unexpected event that terminates processing. For example, SQLite itself runs in several different modes with various levels of guarantees on how failures are handled as follows:
- In-memory journal mode (PRAGMA journal_mode=memory). In this mode any failure may cause database file-system corruption, including an application crash or unexpected exit.
- Non-synchronous mode (PRAGMA synchronous=off). In this mode an application crash or unexpected exit may not cause database corruption, however an operating system crash or power failure may.
- Synchronous mode (PRAGMA synchronous=full). In this mode neither an application crash, operating system crash or power failure may cause database file-system corruption.
If a process attempts to modify a database so as to replace database image A with database image B and a failure occurs while doing so, then following recovery the file-system must contain a database image equivalent to A or B. Otherwise, the database file-system is considered corrupt.
Two database images are considered to be equivalent if each of the following are true:
-
The two database images have the same page-size.
-
The two database images have the same number of pages.
-
The content of each page in the first database image that is not a free-list leaf page is identical to the corresponding page in the second database image.
The exception for free-list leaf pages (see section 2.4) in the third bullet point above is made because free-list leaf pages contain no valid data and are never read by SQLite database readers. Since the blob of data stored on such a page is never read for any purpose, two database images may have a different blob stored on a free-list leaf page and still be considered equivalent. This concept can sometimes be exploited to more efficiently update an SQLite database file-system representation.
Two database images shall be considered to be equivalent if they (a) have the same page size, (b) contain the same number of pages and (c) the content of each page of the first database image that is not a free-list leaf page is the same as the content of the corresponding page in the second database image.
The following requirement constrains the way in which a database file-system representation may be updated. In many ways, it is equivalent to "do not corrupt the database file-system representation under those conditions where the file-system should not be corrupted". The definition of "handled failure" depends on the mode that SQLite is running in (or on the requirements of the external system accessing the database file-system representation).
If, while writing to an SQLite database file-system representation in order to replace database image A with database image B, a failure that should be handled gracefully occurs, then following recovery the database file-system representation shall contain a database image equivalent to either A or B.
The following two sections, 4.1.1 and 4.1.2, are somewhat advisory in nature. They contain descriptions of two different methods used by SQLite to modify a database image within a database file-system representation in accordance with the above requirements. They are not the only methods that can be used. So long as the above requirements (and those in sections 4.2 and 4.3) are honoured, any method may be used by an SQLite database writer to update the database file-system representation. Sections 4.1.1 and 4.1.2 do not contain formal requirements. Formal requirements governing the way in which SQLite safely updates database file-system representations may be found in Not available yet!. An informal description is available in [3].
4.1.1 The Rollback-Journal Method
This section describes the method usually used by SQLite to update a database image within a database file-system representation. This is one way to modify a database image in accordance with the requirements in the parent and other sections. When overwriting database image A with database image B using this method, assuming that to begin with database image A is entirely contained within the database file and that the page-size of database image B is the same as that of database image A, the following steps are taken:
-
The start of the journal file is populated with data that is not a valid journal header.
-
For each page in database image A that is not a free-list leaf page and either does not exist in database image B or exists but is populated with different content, a record is written to the journal file. The record contains a copy of the original database image A page.
-
The start of the journal file is populated with a valid journal header. The page-count field of the journal header is set to the number of pages in database image A. The record-count is set to the number of records written to the journal file in step 2.
-
The content of each page of database image B that is either not present or populated differently in database image A is copied into the database file. If database image B is smaller than database image A, the database file is truncated to the size required by database image B.
-
One of several file-system operations that cause the journal file to become invalid is performed. For example:
- The journal file is deleted from the file-system, or
- The journal file is truncated to zero bytes in size, or
- Some or all of the first 8 bytes of the journal file are overwritten so that the journal file no longer begins with a well-formed journal header (and is therefore not valid).
During steps 1 and 2 of the above procedure, the database file-system representation clearly contains database image A. The database file itself has not been modified, and the journal file is not valid (since it does not begin with a valid journal file header). Following step 3, the database file-system representation still contains database image A. The number of pages in the database image and the content of some pages now resides in the journal file, but the database image remains unchanged. During and following step 4, the current database image is still database image A. Although some or all of the pages in the database file may have been overwritten or truncated away, a valid journal records containing the original database image A data exists for all such pages that were not free-list leaf pages in database image A. And although the size of the database file may have been modified, the size of the current database image, database image A, is stored in the journal header.
Once step 5 of the above procedure is performed, the database file-system representation contains database image B. The journal file is no longer valid, so the database image consists of the contents of the database file, database image B.
Figure 19 depicts a possible interim state of the database file-system representation used while committing a transaction that replaces a four page database image with a three page database image. The contents of the initial database image pages are A, B, C and D respectively. The final database image content is A, E and C. The interim state depicted is that reached at the end of step 4 in the above procedure. In this state, the file-system contains the initial database image, ABCD. However, if the journal file were to be somehow invalidated, then the file-system would contain the final database image, AEC.
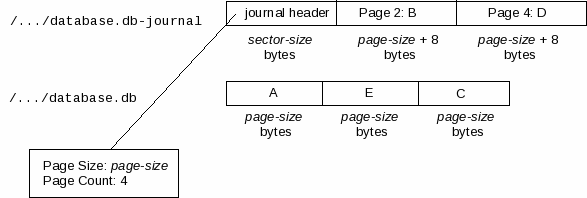
Figure 19 - Interim file-system state used to atomically overwrite database image ABCD with AEC
The procedure described above can be onerous to implement, as it requires that the data for all modified pages of database image B be available (presumably in main memory) at the same time, when step 4 is performed. For transactions that write to a large number of database pages, this may be undesirable. A solution is to create a journal-file containing two or more journal headers. If, while modifying a database image within main-memory, a client wishes to reduce the amount of data held in memory, it may perform steps 3 and 4 of the above procedure in order to write modified content out to the file-system. Once the modified pages have been written into the database file, the in-memory copies may be discarded. The writer process may then continue accumulating changes in memory. When it is ready to write these changes out to the file-system, either to free up main-memory or because all changes associated with the transaction have been prepared, it adds a second (or subsequent) journal header to the journal file, followed by journal records containing the original data for pages about to be modified. It may then write the changes accumulated in-memory to the database file, as described in step 4 above.
This technique can also be modified to support atomic modification of multiple databases. In this case the first 4 steps of the procedure outlined above are followed for each individual database. Following this a master-journal file is created somewhere within the file-system and a master-journal pointer added to each individual journal file. Since a journal-file that contains a master-journal pointer to a master-journal file that does not exist is considered invalid (requirement H32000), all journal-files may be simultaneously invalidated by deleting the master-journal file from the file-system. This delete operation takes the place of step 5 of the procedure as outlined above.
4.1.2 The Atomic-Write Method
On some systems, SQLite is able to overwrite a single page of the database file as an atomic operation. If, while updating the page, a failure occurs, the system guarantees that following recovery, the page will be found to have been correctly and completely updated or not modified at all. When running in such an environment, if SQLite is required to update a database image so that only a single page is modified, it can do so simply by overwriting the page.
Assuming the database page being updated is not page 1, if requirement H33040 requires that the database header change counter be updated, then the database image modification is no longer confined to a single page. In this case it can be split in two: SQLite first atomically updates page 1 of the database file to increment the database header change counter, then updates the page that it is actually required to update using a second atomic write operation. If a failure occurs some time between the two write operations, following recovery the database image may be found to be in its original state except for the value of the database header change counter It would be good to have some requirement to say that that is Ok. Some modification to the definition of equivalent databases perhaps.
4.2 SQLite Locking Protocol
An SQLite database client may hold at any time one of four different types of locks on a database file-system representation. This document does not describe how these locks are to be implemented. Possible implementation techniques include mapping the four SQLite locks to operating system file locks, using an external software module to manage locks, or by creating special "lock files" within the file-system. Regardless of how the locks are implemented, it is important that all database clients in a system use the same implementation. The following table summarizes the four types of locks used by SQLite:
| Lock type | Description | Blocks | Blocked By |
|---|---|---|---|
| SHARED | It is only possible to obtain a SHARED lock if no other client is holding a PENDING or EXCLUSIVE lock. Holding a SHARED lock prevents any other client from obtaining an EXCLUSIVE lock. | EXCLUSIVE | PENDING, EXCLUSIVE |
| RESERVED | A RESERVED lock may only be obtained if no other client holds a RESERVED, PENDING or EXCLUSIVE lock on the database. While a client holds a RESERVED lock, other clients may obtain new SHARED locks, but may not obtain new RESERVED, PENDING or EXCLUSIVE locks. | RESERVED, PENDING, EXCLUSIVE | RESERVED, PENDING, EXCLUSIVE |
| PENDING | It is only possible to obtain a PENDING lock if no other client holds a RESERVED, PENDING or EXCLUSIVE lock. While a database client is holding a PENDING lock, no other client may obtain any new lock. | All | RESERVED, PENDING, EXCLUSIVE |
| EXCLUSIVE | An EXCLUSIVE lock may only be obtained if no other client holds any lock on the database. While an EXCLUSIVE lock is held, no other client may obtain any kind of lock on the database. | All | All |
The most important types of locks are SHARED and EXCLUSIVE. Before any part of the database file is read, a database client must obtain a SHARED lock or greater.
Before reading from a database file , a database reader shall establish a SHARED or greater lock on the database file-system representation.
Before the database file may be written to, a database client must be holding an EXCLUSIVE lock. Because holding an EXCLUSIVE lock guarantees that no other client is holding a SHARED lock, it also guarantees that no other client may be reading from the database file as it is being written.
Before writing to a database file, a database writer shall establish an EXCLUSIVE lock on the database file-system representation.
The two requirements above govern reading from and writing to the database file. In order to write to a journal file, a database client must obtain at least a RESERVED lock.
Before writing to a journal file, a database writer shall establish a RESERVED, PENDING or EXCLUSIVE lock on the database file-system representation.
The requirement above implies that a database writer may write to the journal file at the same time as a reader is reading from the database file. This improves concurrency in environments that feature multiple clients, as a database writer may perform part of its IO before locking the database file-system representation with an EXCLUSIVE lock. In order for this to work though, the following must be true:
-
Database readers must recognize that when a writer holds a RESERVED or PENDING lock on the database file-system representation the writer may be manipulating the journal file and as a result it is not safe to read.
-
Database writers may only obtain a RESERVED or PENDING lock on the database file-system representation when it would be safe for a database reader to assume that the contents of the database file represents the current database image.
The following requirements formally restate the above bullet points.
Before establishing a RESERVED or PENDING lock on a database file, a database writer shall ensure that the database file contains a valid database image.
Before establishing a RESERVED or PENDING lock on a database file, a database writer shall ensure that any journal file that may be present is not a valid journal file.
If another database client holds either a RESERVED or PENDING lock on the database file-system representation, then any journal file that exists within the file system shall be considered invalid.
4.3 SQLite Database Header Cookie Protocol
While a database reader is holding a SHARED lock on the database file-system representation, it may freely cache data in main memory since there is no way that another client can modify the database image. However, if a client relinquishes all locks on a database file-system representation and then re-establishes a SHARED lock at some point in the future, any cached data may or may not be valid (as the database image may have been modified while the client was not holding a lock). The requirements in this section dictate the way in which database writers must update two fields of the database image header (the "cookies") in order to enable readers to determine when cached data can be safely reused and when it must be discarded.
SQLite clients may cache two types of data from a database image in main-memory:
-
The database schema. In order to access database content, the contents of the schema table must be parsed (see section 2.2.3). Since this is a relatively expensive process, it is advantageous for clients to cache the parsed representation in memory.
-
Database image page content. Clients may also cache raw page content in order to reduce the number of file-system read operations required when reading the database image.
Similar mechanisms are used to support cache validation for each class of data. If a database writer changes the database schema in any way, it is also required to increment the value stored in the database schema version field of the database image header (see section 2.2.1). This way, when a database reader establishes a SHARED lock on a database file-system representation, it may validate any cached schema data by checking if the value of the database schema version field has changed since the data was cached. If the value has not changed, then the cached schema data may be retained and reused. Otherwise, if the value of the database schema version field is not the same as it was when the schema data was last cached, then the reader can deduce that some other database client has modified the database schema in some way and it must be reparsed.
Each time a database image stored within a database file-system representation is modified, the database writer is required to increment the value stored in the change counter field of the database image header (see section 2.2.1). This allows database readers to validate any cache of raw database image page content that may be present when a database reader establishes a SHARED (or other) lock on the database file-system representation. If the value stored in the change counter field of the database image has not changed since the cached data was read, then it may be safely reused. Otherwise, if the change counter value has changed, then any cached page content data must be deemed untrustworthy and discarded.
If a database image is modified more than once while a writer is holding an EXCLUSIVE lock, then each header value need only be updated once, as part of the first image modification that modifies the associated class of data. Specifically, the change counter field need only be incremented as part of the first image modification that takes place, and the database schema version need only be incremented as part of the first modification that includes a schema change.
A database writer shall increment the value of the database header change counter field, a 4-byte big-endian unsigned integer field stored at byte offset 24 of the database header, as part of the first database image modification that it performs after obtaining an EXCLUSIVE lock.
A database writer shall increment the value of the database schema version field, a 4-byte big-endian unsigned integer field stored at byte offset 40 of the database header, as part of the first database image modification that includes a schema change that it performs after obtaining an EXCLUSIVE lock.
If a database writer is required by either H33050 or H33040 to increment a database header field, and that header field already contains the maximum value possible (0xFFFFFFFF, or 4294967295 for 32-bit unsigned integer fields), "incrementing" the field shall be interpreted to mean setting it to zero.
5 References
| [1] | Douglas Comer, Ubiquitous B-Tree, ACM Computing Surveys (CSUR), v.11 n.2, pages 121-137, June 1979. |
| [2] | Donald E. Knuth, The Art Of Computer Programming, Volume 3: "Sorting And Searching", pages 473-480. Addison-Wesley Publishing Company, Reading, Massachusetts. |
| [3] | SQLite Online Documentation,How SQLite Implements Atomic Commit, http://www.sqlite.org/atomiccommit.html. |
*** DRAFT ***